2024/04/30
AM中に起床。
掃除したり。
世の中には「気体検知管」
(参考Wikipedia,
使い方)
なるものがあるのを知ったり。ほぅ....
そういえば Emacsの 30系はまだブランチが無いのですが、いつ頃ブランチを分けるのだろうなぁ?
と思ったりも。ここ数週間くらい emacs-develの MLでは MPS(Memory Pooling System)の話題が
沢山投稿されているようですが、30で入れる事になると 結構な大ごとになりそうな予感がしたりも。
2024/04/29
AM中に起床。
そういや日本語入力で変換を伴った場合でも高速に入力する人ってどういう変換をしているのだろうと思って
Web検索してみたり。以下のような動画が見つかりました。
いや、どちらもどうかしてるだろ(褒め)😅
さておき、ある程度の長さで変換している気はするのですが、さすがに初見で誤変換無く動画のような速度で入力できる
とは思えないので、何度か入力して辞書がある程度学習しているものと思われます。
また、実際の読み方とは違う入力をしているのも面白い所かも。「1次」は「1つぎ」を変換していましたが、
確かに「1じ」を変換すると「1時」「1次」「1字」と候補か幾つかあって定まらない可能性が高いと考えられます。
「1次(つぎ)」、「1時(とき)」、「1字(じ)」みたいな使い分けがされてたりするのかしら?と思ったりも。
ところで、どちらも同じソフトを使っているようなのですが、なんてソフトだろうか?
2024/04/28
AM中に起床。
そういえば、MS-IMEでは変換せずに入力を続けていると、ある長さを超えたところで最初の方の文章は自動的に
変換確定してしまいます。
例えば、「日本語ワープロ検定試験」の
1級や初段の速度問題の中には 句点(。)までの一文が長いものがあり、前述した最初の方の自動変換確定が
発動する場合があるようです。
自動変換確定自体にはメリットもあるかと思うのですが、確定する文章の切れ目が句読点というわけでは無いようなのと、
誤変換を含んでいる場合に学習辞書がアホになる可能性が考えられるかと思います。ギリギリ足りないくらいの感じなので、
あとちょっと長い文章を許容したうえで原則として変換タイミングは人が与える事として、
自動変換確定をする場合は句読点までを確定の区切りにした方が良いのではないか?とは思ったりも。
「なんでも鑑定団」を見ていると、ときどき未開封の古いプラモが鑑定品として出てくることがあります。
イマイ(今井科学)やアオシマ(青島文化教材社)は 懐かしいなぁと思う感じです。
で、イマイと言えば
「ロボダッチ」を
連想してしまうTANEなのですが、Webとかでもあまり話題になっているのを見たことは無いなぁ?とは思ったりも。
Wikipediaを読んで知ったのですが、イマイは2002年に解散し、ロボダッチはアオシマの方に引き継がれているようです。
2005年頃にブーム再燃があったようですが、ガンダムに比べれば大分マイナーな感じかも知れません。
マンガやアニメが原作ではなくてプラモメーカーのオリジナルってのも、今じゃ中々無いよなぁと思う所です。
キャラクターの設定があるだけって感じなので「そんなのあったねぇ」以上の思い入れを
TANE自身も持っていないですが😓。
Web散策をしていて いのまたむつみ氏が亡くなっていたのを知ったり
(Wikipedia)。
63歳でしたか。
2024/04/27
AM中に起床。
散髪におでかけ。
JSONフォーマット。テキストベースのデータ記述言語ですが個人的にはあまり触れる事がありませんでした。
Wikipediaによると
「発見」された構造記述言語らしい。
さておき、構造記述としては自由度が高いといいますか、特に配列の要素に構造の違うオブジェクトを
並べて良い為、例えば、
{
"objarray": [
{"key0": "value0"},
{"key1": 1},
2,
{
"key30": "value30",
"key31": 31
}
]
}
のように、配列の各要素の型は揃っていなくても構いません。実際には自由度を縛って使うのかも知れませんが、
フォーマットに完全準拠して扱おうとすると面倒臭い感じかなとは思います。
で、D言語でも std.json というライブラリで
良しなに扱えるようですが、配列を扱う場合は std.json だけでなく std.arrayと std.rangeをimportしないと、
結構面倒臭いかも。あと、要素指定なのか .array に対して操作するのかが分かり難いです。
.arrayに対する操作に統一すれば良いのかも知れませんが。
$ cat -n json_test.d
1 import std.stdio ;
2 import std.json ;
3 import std.array ;
4 import std.range ;
5
6 int main(string[] args)
7 {
8 auto jsond = parseJSON(`{"objarray": [{"key0": "value0"}, {"key1": 1}, 2, {"key30": "value30", "key31": 31}]}`);
9 writeln(jsond);
10 writeln(jsond["objarray"][1]);
11 writeln(jsond["objarray"].array[1]);
12 writeln(jsond["objarray"].array.length); // Not jsond["objarray"].length
13 foreach(n, e; jsond["objarray"].array){
14 writefln("%d: %s", n, e);
15 }
16 jsond["objarray"].array ~= JSONValue(4);
17 jsond["objarray"].array ~= JSONValue(["key5": "value5"]);
18 writeln(jsond["objarray"]);
19 writeln(jsond["objarray"].array.length);
20
21 return 0;
22 }
$ make json_test ; ./json_test
dmd -O -m64 -I. json_test.d
{"objarray":[{"key0":"value0"},{"key1":1},2,{"key30":"value30","key31":31}]}
{"key1":1}
{"key1":1}
4
0: {"key0":"value0"}
1: {"key1":1}
2: 2
3: {"key30":"value30","key31":31}
[{"key0":"value0"},{"key1":1},2,{"key30":"value30","key31":31},4,{"key5":"value5"}]
6
2024/04/26
テレワーク。早めに終了。
Web巡回して終了。
2024/04/25
テレワーク。早くもなく遅くもなく終了。
調べ事をして終了。
2024/04/24
テレワーク。早くもなく遅くもなく終了。
Web巡回して終了。
2024/04/23
テレワーク。早くもなく遅くもなく終了。
MS-IMEで英単語混じりのローマ字入力。
例えば「編集にemacsを使用します」をローマ字入力する場合、キー入力的には
"hennsyuuni「半角/全角」emacs「半角/全角」wosiyousimasu"と入れて変換するのが、
「新しいバージョンのMS-IME」で連続入力する唯一の方法になるかと思います。
「以前のバージョンのMS-IME」であれば
"hennsyuuni「Shift」emacs「Shift」wosiyousimasu"と入力できます。
因みに、"hennsyuuniemacswosiyousimasu"と続けて入れて、後で文節調節して変換しようと思っても、
「emacswo」の部分を「emacすぉ」か「emacswo」にしか調節できなくて詰みます。
これが「編集にEmacsを使用します」であれば、「新しいバージョンのMS-IME」でも
"hennsyuuniEmacs「Shift」wosiyousimasu"と入れて変換できるかと思います。
個人的には 「半角/全角」キーは位置が遠い(1キーの左隣にESCキーを配置するようにキー位置交換しているため)
ので、「Shift」キーでトグルできる「以前のバージョンのMS-IME」の操作方法が合理的に思うのですが、
「新しいバージョンのMS-IME」でも なんとかならんのかなぁ?と思います。
それこそ「Windows」ならまだ良いですが、「macOS」とか「iOS」とかは単語が出てくるたびに ムキー!
ってならないのかしら?
そういえば、「全角/半角」キーの無い USキーボードだと、
ローマ字入力で英単語混じりの長い文章を入力しようと思っても出来ないんじゃないか?と思ったりも。
と考えると「Shift」キーでトグルはやはり合理的だと思います。
2024/04/22
テレワーク。遅めに終了。
調べ事をして終了。
2024/04/21
AM中に起床。
掃除したり。
そうえば以前、MS-IMEで単語単位で変換するよりは、
長い文章で入力し(いわゆる連文節変換)、誤変換がある場合は確定する前にIME上で修正した方が良いだろう、
ということで 意識して長い文章を入れるようにしてみています。
ローマ字入力では英文字交じりの文章を入力するのは面倒くさい所もあるので、
気づかないうちに文章の途中で変換確定してしまう事もありますが、
以前よりは長い文章を入れてから変換確定していると思います。
心なしか選ばれる単語の誤変換が減ったような気もするのですが 気のせいかもしれません😅。
ただ、同音異義語の中でも文脈を正確に読み取らなくてはならないものは、
自分で正解を判断するしかありません。
2024/04/20
AM中に起床。
昔書いたHTMLファイルでcharsetを指定していないものがあり、それをEmacsのewwで表示すると
エンコードがうまくできませんでした。eww本体には Eキー(==コマンドeww-set-character-encoding)
を押すことでエンコードを指定できるようなのですが、指定しても変化が無いなぁ?という感じに。
調べてみたところ、ローカルファイルを表示している場合には指定したエンコードが
反映されるようになっていないみたい。以下のように直してみました。
$ diff -u lisp/net/eww.el.orig lisp/net/eww.el
--- lisp/net/eww.el.orig 2024-03-24 23:48:30.261937900 +0900
+++ lisp/net/eww.el 2024-04-20 15:43:25.115371700 +0900
@@ -1336,7 +1336,7 @@
;; doesn't work well with Tramp files).
(let ((eww-buffer (current-buffer)))
(with-current-buffer (eww--file-buffer (url-filename parsed))
- (eww-render nil url nil eww-buffer)))
+ (eww-render nil url nil eww-buffer encode)))
(let ((url-mime-accept-string eww-accept-content-types))
(eww-retrieve url #'eww-render
(list url (point) (current-buffer) encode))))))))
ちょっと使ってみた範囲では大丈夫そうなのですが、常にencode指定される感じになるので
もしかすると副作用があるかも知れません。御参考まで。
2024/04/19
テレワーク。遅めに終了。
そういえば、Cygwinでは Emacsからflake8を普通に実行できますが、
MinGWの Emacsで実行できるんだっけ?と思ったりも。
以前知った通り、実行の仕方によっては
「#!」(シェバン)で実行するように書かれたスクリプト系言語は実行できないのですが、
pythonを使ったコマンドは大体スクリプトのままなのでダメな気がしたり。
ちょろっと試した感じではダメそう。
2024/04/18
テレワーク。遅めに終了。
どうやらpyflakesで実行しているのは標準の lisp/progmodes/python.el の中で
セットアップされたflymake-modeが機能しているからでした。
カスタム変数 python-flymake-command がpyflakesを使用するようになっているので、
flake8を使用するように変更すれば良い模様。.emacsに
(setq python-flymake-command '("flake8" "-" "--color=never"))
てなのを1行足せば良いみたい。
flake8の引数「-」は標準入力からの読み込みになっていて、リモートファイルを開いたバッファを
パイプを介してローカルマシンのflake8でチェックするという仕組みのようです。
ただし、flymake-python-pyflakesと違って なんでもかんでも error で表示されます。
でも、仕組みが判ったので flymake-python-pyflakes をリモートファイル対応に改造してみるのはアリかも?
2024/04/17
テレワーク。早くもなく遅くもなく終了。
何気にリモートのpythonコードを開いてデバッガ(pdb)を起動するとステップ実行できるな?
と思ったり。ほぅ...。リモートのpythonコードに対してはflymakeによる文法チェックがで
きない(2017年7月頃バージョンのflymake-python-pyflakesを使用)のですが今だとできるのか?
ちょっと調べて試してみたのですが、リモートファイルに対するflake8ではなにやら実行がうまくいかなくて、
代わりにpyflakesの結果が出力されている模様。pyflakesが実行できるならflake8も実行できるんじゃないのか?🤔
2024/04/16
テレワーク。遅めに終了。
調べ事をして終了。
2024/04/15
テレワーク。遅めに終了。
ノートPCの Windows11 23H2がまた来ていたのですが、やっぱりダウンロードに失敗。
0x80246019ってコードみたいなのですが、検索すると面倒な修復方法しか出てこない。
あれこれやり方があるようですが、事実上インプレースアップグレード一択なんじゃないか?
ほっといたところで修復されるとも思えないので、
ISOイメージをマウントするインプレースアップグレードを行なう事にしてみたり。
40分ほどで完了。 システム表示上は 23H2になったのですが、
見た目などには特に変化は無し。一体何に突っかかっていたのか不明なレベル。
2024/04/14
AM中に起床。
「ダンジョン飯」のアニメ。1クール目の大分後から見始めたので、ストーリー序盤の
事情はよく判っていないのですが、魔物を調理する設定もさることながら
魔法やダンジョンの成り立ちといった世界観の設定も面白いなぁと思って観ています。
原作は2023年に完結しているらしい。
Blender弄り。操作方法を示したWebページは沢山あり、操作方法がGIFアニメーション化されているものも
あるのですが、操作が速すぎて何やっているのかよく判らないものもあります。
スロー再生か一時停止したくなるのですがブラウザの機能でできないんだっけ?と思って調べて
みるも標準機能では出来なさげ。仕方ないのでGIF画像ファイルをセーブして Emacsで表示した後、
fとかbでフレームを進めたり戻したりして観察したり。
てか、Emacsでもできるような事はブラウザの標準機能として出来て欲しいところです。
Blenderでなにやらビューポート表示とレンダリング表示とで結果が違うなぁ?と思って、計算を間違えているのか?
とか色々弄ったのですが、原因は実験でモデリングした分を「ビューポートで隠す」にしていたのですが、
「レンダーで無効」にするのを忘れていただけでした😓。これまでにも何度もやらかしているのですが、
微調整をしているような場合は 微妙なズレのようにレンダリングされるのでやらかしている事に
気づかない事が多いです😓。
配列モディファイヤーを使って円形のカーブに沿わせようとすると、始点と終点を合わせるのが
地味に面倒臭いです。円周の長さはどうしても円周率が掛かるので、例えば直径 φの円であれば
配列要素数をNとした場合、一つのオブジェクトの長さLを、L=φπ/N となるようにすれば良いと
思う訳ですが 絶対にピッタリ割り切れるような値にはなりません。
いずれにしても、完全に継ぎ目を消すのは無理があるなぁ?と思ったりも。

モディファイヤーを適用した後に手作業でメッシュを繋げば良いのかも知れませんが、
継ぎ目が見えないように隠せるならば そこまで気を使う必要は無いのかも知れません。
時と場合によるという感じかも。
2024/04/13
昼前起床。
掃除したり。
ぐうたら過ごして終了。
2024/04/12
テレワーク。遅めに終了。
ノートPCに Windows11の23H2がやっと来た....と思ったら何故か更新に失敗して再試行したら
22H2の累積アップデートが始まったり。再起動して22H2のアップデートは終わったのですが、
23H2へのアップグレードは出てこなくなったり。なんだこれ?
Revision 2024の wild demo作品 「scrolll」。
アイデアが面白いと思うのと同時に、スクロールバーなので長さは変えられても同じレーンに
複数のバーを入れる事はできないので、良い感じの絵を出すのは意外と難しい(センスを問われる)
のではないかと思ったりも。
2024/04/11
テレワーク。気持ち遅めに終了。
ちょろり調べ事。
2024/04/10
テレワーク。早くもなく遅くもなく終了。
SAI2の新しいのがリリースされていたり。バグ修正リリースの模様。
調べ事。
2024/04/09
テレワーク。早くもなく遅くもなく終了。
調べ事をして終了。
2024/04/08
テレワーク。早くもなく遅くもなく終了。
Web巡回して終了。
2024/04/07
AM中に起床。
掃除したり洗濯したり。
SAI2の新しいのがリリースされていたり。おつかれさまです。今回は緊急リリース的な感じでしょうか。
バグ修正とブリスルデータの修正ツールのリリースの模様。
何気に競技プログラミングのこの問題を、
D言語で以下のような感じに書いてみていたのですが、
:
int[] res;
foreach(a; Ax)
if(a%K==0)
res ~= a/K;
writefln("%(%s %)",res);
std.algorithm.iteration に filterってのがあるのを知り、
:
writefln("%(%s %)", Ax.filter!(a => a%K==0).map!(a => a/K));
って感じでも書けると思ったり。前者は条件を満たしていたら値を加工して覚えておく
という考え方ですが、後者は条件を満たしている値を覚えておいて後でまとめて加工する
という考え方になるかと思います。ただ、結果の出力フォーマットが「値を空白で区切る」
となっているので、どちらも その為だけに 結果となる値群を全部覚える感じになっているのですが、
値毎に改行で区切って出力するのであれば、絶対に後者は使わないだろうなぁとは思ったりも。
ところで、「区切り文字で区切って並べろ」は 最後の要素か否かで処理を変える必要があるので
地味に面倒臭い要件だと思います。
そういえばD言語の string型は UTF8ですが、文字列の切り出しはスライスを使うって感じになっています
(例 "abcdefgh"[2..5] とか)。でも、.lengthプロパティの値は配列の長さであって文字数ではありません。
この為、スライスでは 日本語や絵文字が含まれていると文字単位で切り出せないよなぁ?と思ったりも。
何か定石があるだろうと思って検索してみるも何故か思った感じに扱う例が無いようだったり。
因みにELISPでは文字単位という扱いになっています。
(length "🥺あいうえお🤔") ;and press C-j
7
(substring "🥺あいうえお🤔" 3 (+ 3 4)) ;and press C-j
"うえお🤔"
ただし、絵文字の合字は1文字扱いにならない為「(length "👨🌾")」は3が返り、
「(length "👨👩👧👦")」は7が返ります。
D言語での文字列切り出し。std.rangeの take(),drop()を使えば部分切り出しを間接的に行なう事は可能みたい。
tail()という文字列の最後から指定文字数を切り出す事もできるようですが、文字列の長さを調べる方法は
何故か判らず。
import std.stdio;
import std.string;
import std.array;
import std.range;
void main(string[] args)
{
string str = "🤔あいうえお🥺";
writeln(str.take(3)); //🤔あい
writeln(str.drop(3)); //うえお🥺
writeln(str.tail(2)); //お🥺
writeln(str.drop(3).take(2)); //うえ
}
何かしら応用の範囲内なのだろうか?🤔
2024/04/06
起きたら午後もいい時間。寝すぎ。
すっかり忘れていたのですが、dmdってデフォルト32bitコンパイルだったか。
そして気づいていなかったのですが、ldc2ってデフォルト64bitコンパイルになっているのか。
配列の要素指定にlong型の変数を使用するようなコードがあったのですが、
ldc2だと大丈夫だけど dmdだとエラーになったのでなんでだっけ? というので気づきました。
2024/04/05
テレワーク。早くもなく遅くもなく終了。
以前、Cygwinネイティブではない
Windowsアプリのターミナル出力は文字コード変換が行なわれていて、
ターミナルがUTF8対応していたとしてもTTY出力では文字が化けるってのを知りました。
で、C言語で言う 関数setmode()でバイナリ出力するとかではコントロールできないのだろうか?
と思い少し試してみました。結果はなんかうまくいかないという感じです🥺
$ cat charcode_test.d
import std.stdio;
import std.string;
void main(string[] args)
{
if(args.length>=2){
switch(args[1]){
case "u8text": _setmode(1, _O_U8TEXT); break;
case "binary": _setmode(1, _O_BINARY); break;
default: break;
}
}
writef("This is D言語 🙂\n");
}
$ ldc2 -O -I. charcode_test.d
Emacsのvterm(UTF8ターミナル相当)で実行してみた結果が以下の画像。
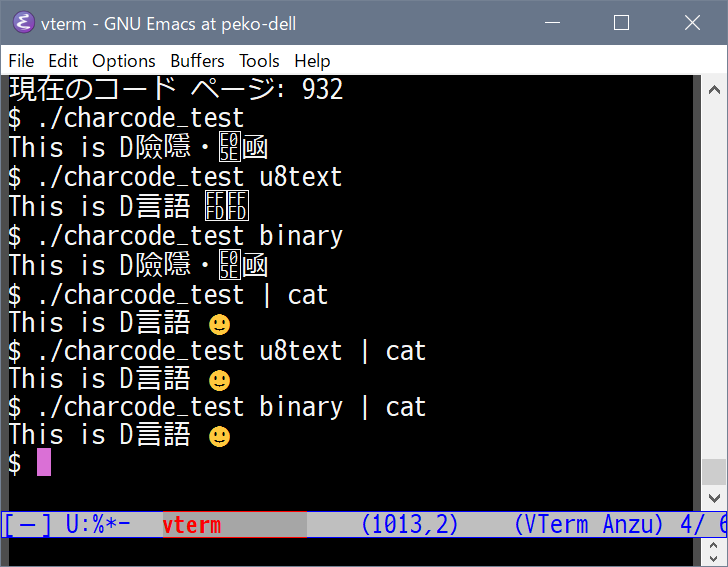
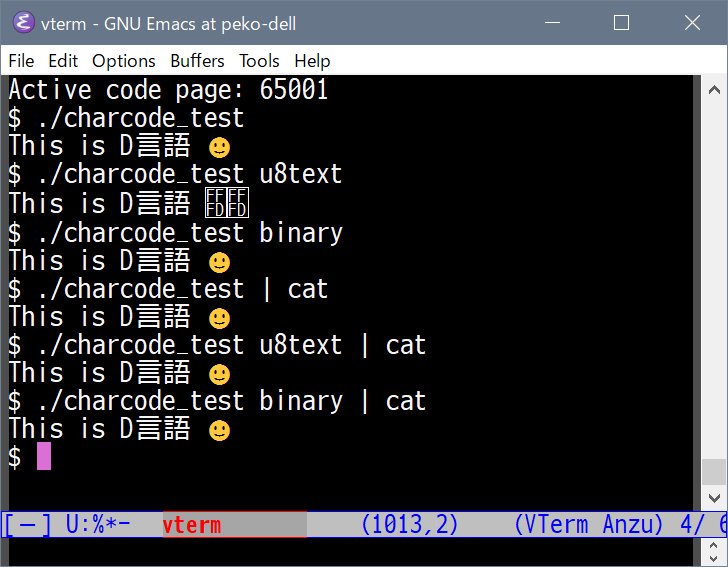
chcp設定が cp932でも setmode()を_O_U8TEXTにすれば 「言語」はうまく表示されるのですが、
絵文字が表示不可となります。
chcp設定が 65001(==utf8)の場合でも、setmode()を _O_U8TEXTにするとやっぱり絵文字が表示不可となります。
いずれもパイプを介して catで出力したものでは 絵文字も化けません。
_O_U8TEXTで絵文字が化けなければそれで十分なのに。あ、改行コードがCRLFになるのは嫌かも。
どれもイマイチでうまくいかないもんです🥺
2024/04/04
テレワーク。気持ち早めに終了。
ちょろり調べ事。
2024/04/03
テレワーク。早めに終了。
Web巡回して終了。
2024/04/02
テレワーク。気持ち早めに終了。
すっかり忘れていたのですが Revision 2024。終わってました😅。
Pouetの方に結果が出ていますが
毎度の事ながら多いです。
256bの1位作品「Remnants」に驚きました。
他もゆっくり観てみようと思います。
2024/04/01
テレワーク。気持ち早めに終了。
調べ事をして終了。