バイトオーダーの雑記
目次
1 はじめに
CPUでメモリアクセスを行う際にバイトオーダーを意識しなくてはならない場合があります。 よくメモリダンプの表示に対して「リトルエンディアンだとひっくり返して読む」なんて 事が言われますが、なんでそんな事になってしまってるのか?って所を、独自の見解を踏まえて 記してみたいと思います。
本文書では、16進数をXXXXh、10進数をXXXX、2進数をXXXXbと表現します。
2 バイトオーダーとビットオーダー
バイトオーダー(バイト順)は、メモリ上のデータの並びの事を指します。 大きくビッグエンディアンとリトルエンディアンの二種類の方式があります。
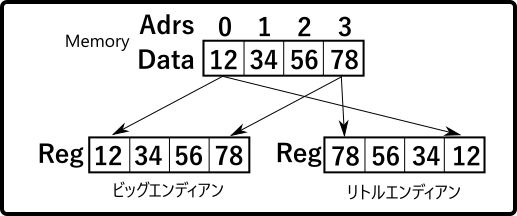
メモリ上のデータをレジスタ(図では4バイト)にロードする際に、ビッグエンディアンと リトルエンディアンではデータの並びが異なります。
- ビッグエンディアン : メモリアドレスの昇順のデータ並びがレジスタの左から右に向かってロードされる。
- リトルエンディアン : メモリアドレスの昇順のデータ並びがレジスタの右から左に向かってロードされる。
ビッグエンディアンはIBMのPOWER/PowerPCなど、リトルエンディアンはIntelのx86などで 採用されています。ちなみに、モトローラのm68kや、SunのSPARCも一般的には ビッグエンディアンなのですが、後述するビットオーダー表現に於いてリトルエンディアン の要素を含んでいます。
メモリのデータ並びに対して、リトルエンディアンがひっくり返っていると言われる 所以であると考えられます。
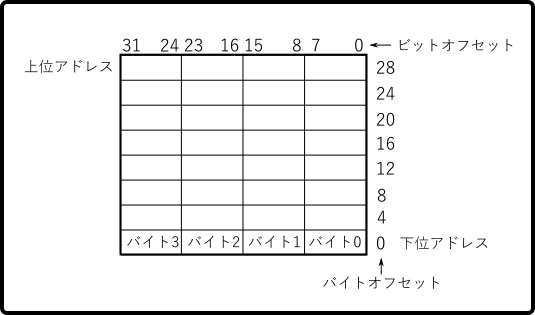
エンディアンというと暗にバイトオーダーの事を指すようですが、 ビットオーダー(ビット順)にも違いがあります。 IA-32のソフトウェア・デベロッパーズ・マニュアルでは、ビットオーダーと バイトオーダーについて、次のように規則が示されています。
また、PowerPCではレジスタのビットオーダーは以下のように示されています。
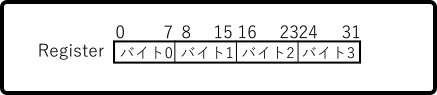
PowerPCでは MSB(Most Significant Bit/最上位ビット/左端ビット)のビットを0、 LSB(Least Significant Bit/最下位ビット/右端ビット)のビットをNとするのに対し、 IA-32ではMSBのビットをN、LSBのビットを0とします。ビットオーダーについては ビッグエンディアン/リトルエンディアンという言い方はあまり使わないようですが、 本文書では以降、MSB=0且つLSB=Nとする場合にもビッグエンディアン、MSB=N且つLSB=0とする 場合にもリトルエンディアンと呼ぶ事とします。
例えば「4バイトデータの15ビット目を1にする」と言った場合、 00010000h か、00008000h かの違いが出てきます。
3 メモリマップの表現
システムのメモリマップを表現する際も 二種類の表現があります。
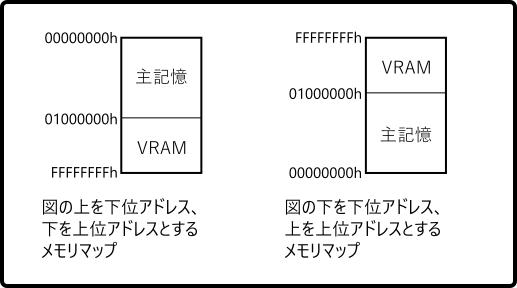
ビッグエンディアンのPowerPC系のマニュアルでは、図の上を下位アドレスとする 表現で統一されているようです。IA-32のマニュアルでは、図の下を下位アドレスと する表現で統一されているようです。
因みに、図の下を下位アドレスとする表現は、1986年に発売されたPC-8801FH/MHという Z80系CPUを使用した8bitパソコンのプログラマーズ・ガイドのメモリマップでも使用されて います。この事からも随分前から存在する表現だと考えられます。
メモリやファイルの内容を16進ダンプ表示するプログラムでは、画面の上を下位アドレス として表示するものがほとんどです。しかし、この表示方法を基準にしてしまうと、 リトルエンディアンではバイト並びがひっくり返っているように見える事になります。
4 値の表現
2進数を10進数に変換する場合、以下のように一般化できます。
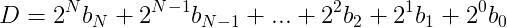
例えば4ビットの1010bという2進数の場合、
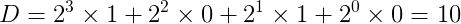
となります。
この式では ビットオーダーをリトルエンディアン(MSB=N且つLSB=0)で考える事により 数式として2進→10進変換を一般化できます。 ところが、ビットオーダーをビッグエンディアン(MSB=0且つLSB=N)にしてしまうと、 数式として2進→10進変換を一般化できなくなってしまいます。
5 文字列の表現
コンピュータ上では 文字毎に値を対応付けて表現しています。値に対応する文字画像(フォント)を ディスプレイ上に表示する事で人の目で見られるようになります。文字の集まりを文字列と 呼びます。
例えば「This is a pen.」はメモリ上では 「54h 68h 69h 73h 20h 69h 73h 20h 61h 20h 70h 65h 6eh 2eh」という値が並んでいる として扱っています。「pen」を「cat」に変える場合は、メモリの「70h 65h 6eh」の部分を 「63h 61h 74h」に変える事で実現されます。いわゆる「文字列の置換操作」はメモリ の内容を書き換えているに過ぎません。
ところで、英語や日本語の横書きの場合、左から右に向かって文字を書き連ねます。 文字の集まりが単語であり、単語の集まりが文という事になります。 そして行は下に向かって増えます。
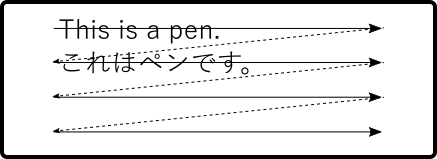
メモリを原稿用紙のようなイメージで考えた場合、多くの人にとっては 左上を始まり、右下を終わりとなっているのが自然に見えると思われます。 自然と感じるのは人間の言語文化による所が大きいと考えられます。
6 16進ダンプ表示の仕方
メモリを1バイト単位でしか扱わないのであれば バイトオーダーがビッグエンディアンでも リトルエンディアンでも違いはありません。しかし、2バイト以上の値を扱ったり、 2バイト以上を使用して文字表現を行うする場合に違いが出てきます。
メモリやファイルの16進ダンププログラムでは、ほぼ例外無く表示画面の左上をメモリの始まり (下位アドレス)、右下をメモリの終わり(上位アドレス)として表示します。 人間の都合で考えた場合、文字列として見る場合やビッグエンディアンの値として見る 場合には 都合良く読むことができます。しかし、リトルエンディアンの値として見る と読みにくくなってしまいます。
「バイトオーダーとビットオーダー」や「メモリマップの表現」の項で述べた通り、 Intel系CPUのマニュアルには、メモリのイメージは下から上にアドレスが増加するように 描かれています。それにもかかわらず、ファイルやメモリのダンププログラムは 画面の左上を下位アドレス、右下を上位アドレスとして表示するものばかりです。 そんな訳で、ファイルの16進表示プログラムを作ってみました。
例えば次のようなC言語のプログラムを、
#include <stdlib.h> #include <stdio.h> int main() { short membuf[256] ; int i ; FILE *ofp ; for( i=0 ; i<256 ; i++ ){ membuf[i]=i ; } if( (ofp=fopen("memdump.bin","w"))==NULL ){ printf("file open failed\n") ; exit(EXIT_FAILURE) ; } fwrite(membuf,sizeof(short),256,ofp) ; fclose(ofp) ; return(0); }
リトルエンディアンアーキテクチャのマシンでコンパイル&実行して得られた バイナリファイルを表示した例を示します。
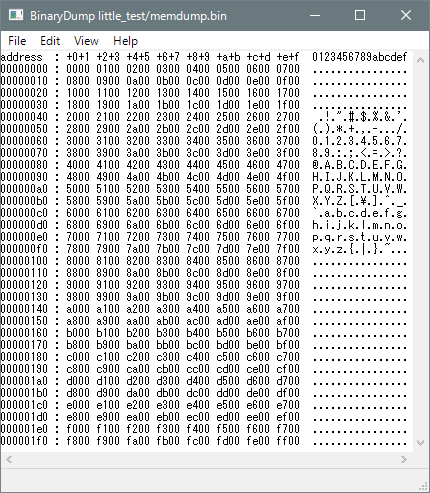
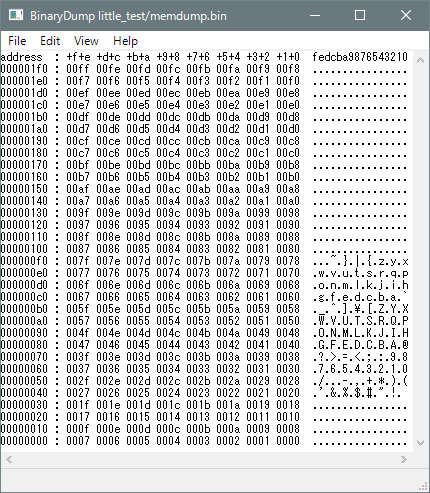
左が2byte区切りのビッグエンディアン表示(いわゆる普通の16進ダンプ表示)、 右がリトルエンディアン表示です。 慣れが必要ですが リトルエンディアン表示だと見た目で読める ように値が並んでいると思います。
7 まとめ
値表現で見るとリトルエンディアンは辻褄が合っているのに、文字列として見ると 都合が悪く見える原因の一つに、数字は大きな桁を左、小さな桁を右に表現している 点が挙げられると考えられます。もし、1234(千二百三十四)を 4321 と書く言語文化 だったならば、ビットオーダーをリトルエンディアンにするという考え方は 生まれず、ビットオーダーがビッグエンディアンでも 2進→10進変換を一般式化 できたのかも知れません。もしくは、数字表現はそのままに、文字列も 右下から左上に向かって記す言語文化だったならば、ビッグエンディアンの考え方は 生まれず、コンピュータ画面のホームカーソル位置は右下にあり、下に向かってスクロール していたかも知れません。
以上より、個人的な見解となりますが、
- 日本語の横書きや英語では、文字列の進む方向と 数値の桁の増える方向が互い逆である。 この為、16進ダンプで文字列優先で表示すると数値の桁が入れ替わり、数値優先で表示 すると文字列の並びが逆になる。
- コンピュータ有史以来、画面出力は文字列表示優先となっている。この為、 左上から右下に向かって表示するのが当たり前となっている。
という辺りが、リトルエンディアンがひっくり返りに見える理由になっていると 考えます。
しかしながら、どちらのエンディアンでも、ある特定のCPUアーキテクチャに閉じた世界で 値を扱う場合はあまり問題になりません。ビッグエンディアンとリトルエンディアンを 行き来するような場合、例えば アーキテクチャがビッグエンディアンのコンピュータで生成したファイルを、 リトルエンディアンのコンピュータで読み込むような場合に、 少し面倒臭い事があるといった程度の些細な問題(ただしハマるとなかなか気づかない) と考えられているように思われます。
8 16進ダンプ表示プログラムについて
作成した16進ダンププログラムを公開しておきます。
bindump.exeがGUI版、bdump.exeがコマンドライン版です。 ファイルエクスプローラなどからbindump.exeを実行するとウインドウが開きます。 ダンプを見たいファイルをFile→Openから開くか、ドラッグ&ドロップすると表示されます。 View→Big-Xbyte,Little-Xbyteで表示を切り替えられます。
GUI版は表示するだけで、表示文字をコピーしたり検索したりはできません。 その場合はコマンドライン版のbdump.exeをCygwinやMSYS2のコマンドライン から使用するのが良いかも知れません。
$ ./bdump.exe --help
Usage: bdump [OPTION]... [FILE]...
Dump files in Hex formats
-s n, --size n Size bytes per integer(n=1 or 2 or 4 or 8)
-l , --little Little endian dump mode.
-V , --version Print version.
-h , --help Print this help.
$ ./bdump.exe -l -s 2 little_test/memdump.bin
address : +f+e +d+c +b+a +9+8 +7+6 +5+4 +3+2 +1+0 fedcba9876543210
000001f0 : 00ff 00fe 00fd 00fc 00fb 00fa 00f9 00f8 ................
000001e0 : 00f7 00f6 00f5 00f4 00f3 00f2 00f1 00f0 ................
000001d0 : 00ef 00ee 00ed 00ec 00eb 00ea 00e9 00e8 ................
000001c0 : 00e7 00e6 00e5 00e4 00e3 00e2 00e1 00e0 ................
000001b0 : 00df 00de 00dd 00dc 00db 00da 00d9 00d8 ................
000001a0 : 00d7 00d6 00d5 00d4 00d3 00d2 00d1 00d0 ................
00000190 : 00cf 00ce 00cd 00cc 00cb 00ca 00c9 00c8 ................
00000180 : 00c7 00c6 00c5 00c4 00c3 00c2 00c1 00c0 ................
00000170 : 00bf 00be 00bd 00bc 00bb 00ba 00b9 00b8 ................
00000160 : 00b7 00b6 00b5 00b4 00b3 00b2 00b1 00b0 ................
00000150 : 00af 00ae 00ad 00ac 00ab 00aa 00a9 00a8 ................
00000140 : 00a7 00a6 00a5 00a4 00a3 00a2 00a1 00a0 ................
00000130 : 009f 009e 009d 009c 009b 009a 0099 0098 ................
00000120 : 0097 0096 0095 0094 0093 0092 0091 0090 ................
00000110 : 008f 008e 008d 008c 008b 008a 0089 0088 ................
00000100 : 0087 0086 0085 0084 0083 0082 0081 0080 ................
000000f0 : 007f 007e 007d 007c 007b 007a 0079 0078 ...~.}.|.{.z.y.x
000000e0 : 0077 0076 0075 0074 0073 0072 0071 0070 .w.v.u.t.s.r.q.p
000000d0 : 006f 006e 006d 006c 006b 006a 0069 0068 .o.n.m.l.k.j.i.h
000000c0 : 0067 0066 0065 0064 0063 0062 0061 0060 .g.f.e.d.c.b.a.`
000000b0 : 005f 005e 005d 005c 005b 005a 0059 0058 ._.^.].\.[.Z.Y.X
000000a0 : 0057 0056 0055 0054 0053 0052 0051 0050 .W.V.U.T.S.R.Q.P
00000090 : 004f 004e 004d 004c 004b 004a 0049 0048 .O.N.M.L.K.J.I.H
00000080 : 0047 0046 0045 0044 0043 0042 0041 0040 .G.F.E.D.C.B.A.@
00000070 : 003f 003e 003d 003c 003b 003a 0039 0038 .?.>.=.<.;.:.9.8
00000060 : 0037 0036 0035 0034 0033 0032 0031 0030 .7.6.5.4.3.2.1.0
00000050 : 002f 002e 002d 002c 002b 002a 0029 0028 ./...-.,.+.*.).(
00000040 : 0027 0026 0025 0024 0023 0022 0021 0020 .'.&.%.$.#.".!.
00000030 : 001f 001e 001d 001c 001b 001a 0019 0018 ................
00000020 : 0017 0016 0015 0014 0013 0012 0011 0010 ................
00000010 : 000f 000e 000d 000c 000b 000a 0009 0008 ................
00000000 : 0007 0006 0005 0004 0003 0002 0001 0000 ................
本プログラムはD言語 を使用して作成しました。 アーカイブにはソースコードも含まれていますが、コンパイルには以下の Win32APIバインディングのソースが別途必要です。
ビルド方法は以下の通り。例では ~/Downloads/ の下にtar.xzアーカイブをダウンロード したとします。作業ディレクトリは適当な場所だとします。
xz -dc ~/Downloads/bindump_v001.tar.xz | tar xf -cd bindump_v001/srcxz -dc ~/Downloads/win32-r433b.tar.xz | tar xf -./mk.sh -a
MinGW-gdc-2.066.1(MSYS2でビルドしたMinGWネイティブコンパイラおよび CygwinでビルドしたMinGWクロスコンパイラ)でビルド確認 しました。オリジナルのDMDでコンパイルできるかは確認していません。
既知の問題
- bindump Ver0.01
- 巨大サイズのファイルを何度も読み直しているとメモリ不足で落ちる場合があります。 また、32bitアプリとしてコンパイルしていますので、2GB以上のファイルを表示したい場合は64bitコンパイルし直す 必要があります。
- bdump Ver0.01
- 「
bdump foo.bin | less」 のようにパイプで標準出力を次のプログラムに渡した場合、 最後まで表示する前に 次のプログラムを終了した際に 「Failed to flush stdout: Invalid argument」といったメッセージが表示される場合があります。
- 「
9 終わりに
随分前 にリトルエンディアン で2バイト以上の値を 16進ダンプすると上下がひっくり返って格納されているのは、 表示の仕方の問題じゃないの?という事を書いたのですが、特に何かある訳でもなく そのまま忘れていました。その後、インテル系CPUのプログラマ向けマニュアルを 読んでいて、メモリマップやバイトオーダーについて但し書きがあるのを見つけ、 やっぱそうなんだと思い、メモっておこうと作成したのが本文書です。
リトルエンディアンとビッグエンディアン(と例外的なミドルエンディアン)の話は 随分前からあるのですが、それぞれが生まれた理由や経緯について聞いたことは ありません。この為、本文書でも文字列と数値とでは並びが逆である点が理由の 一端にあるとしました。しかしながら、CPUメーカー各社がそれぞれリトルエンディアン もしくはビッグエンディアンを採用した理由というのは知りたいなぁ と思う所です。