昼前起床。寝すぎ。
Emacsのフォントフォールバックでみつけられないフォントファミリの件。
結局、どうにもうまく見つけられそうにないのと、見つけられたとしても時間がかかる事を鑑みると、
豆腐になるユニコード文字が表示可能なフォントはWebで検索して調べ、
必要に応じてフォントをインストールした後、.emacsに
「(set-fontset-font t '文字セット "フォントファミリ名")」
を記す事で対応するのが、普段使いする事を考えると一番良いのではないか?という気がしてきました😓。
という訳でこの件については一旦終了。
フォントフォールバックに時間がかかる件の対応について。
以前、表示はされるけど どの文字で時間がかかっているのか判らないので、
set-fontset-fontでの対応のしようが無い....という事になっていました。
そこで、時間がかかる場所の時間計測が可能なので、何かしら対処の手掛かりとなるようなメッセージを
出せないかと考えてみました。一応出せそうな所までは出来たものの、
メッセージを 関数message()で出力しようとすると Emacs本体が落ちるという現象に見舞われています🥺。
原因がよく判っていないのですが、画面表示が行なわれていない状態で message()を何度も
行なうとダメなのでは?という気がしたりも。
そういえば、フォント関連のソースを弄っていて、ところどころに FONT_ADD_LOG()というマクロ関数を
使って何かしら記録を取っているように思ったのですがスルーしていました。
先の message()を使えない代わりに、このログを取る仕組みに乗っかるのはどうか?と思って
ログの表示方法を調べてみたり。
infoに使い方が見当たらなかったので helpで調べながら試してみたところ、
組み込み変数font-log をnilにするとフォント関連操作のログが取られるようになり
(デフォルトはtで記録抑止の状態。なんか意味的に逆じゃないか?)、
「M-x font-show-log」で記録したログが表示されるようです。
という訳で、フォントログに記録してみるようにしたところイケたかも。
次のような感じで使う想定。Emacs起動後、scratchバッファなどで以下のようなロギング設定をする。
(progn (setq font-log nil) (setq debug-font-find-time-limit 900) ;今回追加した設定変数. 900msより時間がかかるとログに記録する. ) ; and press C-j
font_find_for_lface: exec time 6892.0ms > 900.0ms char=0x1787 (#<font-entity harfbuzz outline Leelawadee UI sans iso10646-1 regular normal normal 0 nil 0 nil ((:format . opentype) (:script symbol buginese khmer lao thai latin))>)
(set-fontset-font t 'khmer "Leelawadee UI")
テレワーク。早めに終了。
Emacsのフォントフォールバックでみつけられないフォントファミリの件。
ふんわり次のような感じなのかなぁ?
関数font_has_char()では 文字が含まれるフォントが指定してあれば表示可能と判断されるようですが、
フォントの指定がデフォルトフォントだけなので、それだと結果的に表示可能と判断されず。
続いて関数font_list_entities()でより多くのフォントを探して、その中から表示可能な物を選択する
と思われます。しかし、フォントのリストを取得する 関数 w32font_match_internal()では
Win32APIの EnumFontFamiliesEx() でCHARSETなどから探そうとするようなのですが、
ここで「Noto Sans Modi」をリストに挙げることができず、結果的に表示可能なフォントが無いと
判定されてしまう....という感じかな?
khmer文字で時間がかかっていたのは、w32font_match_internal()でのフォントリストに
インストールされている全てのフォントが含まれていて、この中から実際に表示可能なフォントに
到達した結果「Leelawadee UI」が選ばれるという感じのようでした。
無理矢理全部入りフォントリストを渡せば見つけられるのだろうか?🤔
テレワーク。気持ち早めに終了。
Emacsのフォントフォールバックでみつけられないフォントファミリの件。
観察してみてますが特に進展無し。
テレワーク。気持ち早めに終了。
Emacsのフォントフォールバックでみつけられないフォントファミリの件。
動きを観察してみるものの、まだよく判らず。
以前、例えばkhmer文字を表示できるフォントを見つけるのに
関数font_find_for_lface()で大量のフォントファミリ群の中から探していて、
それで時間がかかるという感じになっていました。しかし、modi文字の場合は font_find_for_lface()で
時間がかからずにそして何もみつけられずに終了している感じになっているみたい。
khmer文字と同じ感じならmodi文字も同じように探すんじゃないか?と思った訳ですが、
この違いがどこから生じるのかがまだ不明という感じです。
テレワーク。気持ち早めに終了。
Emacsのフォントフォールバックでみつけられないフォントファミリの件。
多分こうなんじゃないか?という感じ。
src/fontset.c内の 関数fontset_find_font()でフォールバックした時のフォントを探しているようですが、
その中で font_has_char()という関数を使って 文字がフォントオブジェクトに含まれるかどうかを検査しているようです。
src/font.c内に 関数font_has_char()の実体は存在していて、この中では更にフレーム表示に紐づけられる
フォントドライバの持つ has_char()という下請け関数を実行しているようです。
harfbuzzの場合は has_char()の実体は持たないようなので、その時点で検査不可能で終了...って
訳では無いようで、代わりに フォントドライバの持つ encode_char()という下請け関数を実行して
検査している模様。encode_char()の実体は src/w32uniscribe.c内の 関数w32hb_encode_char()で、
どうやらここで FONT_INVALID_CODEとなってしまった結果、表示可能なフォントが無いという判定になっているようです。
実際の検査は以下のようなコードで行なっていました(デバッグ表示コードが盛られています😓)。
hb_codepoint_t glyph;
if (hb_font_get_nominal_glyph (hb_font, c, &glyph))
return glyph;
fprintf(stderr,"w32hb_encode_char c=%x invalid_code2\n",c); //debug
return FONT_INVALID_CODE;
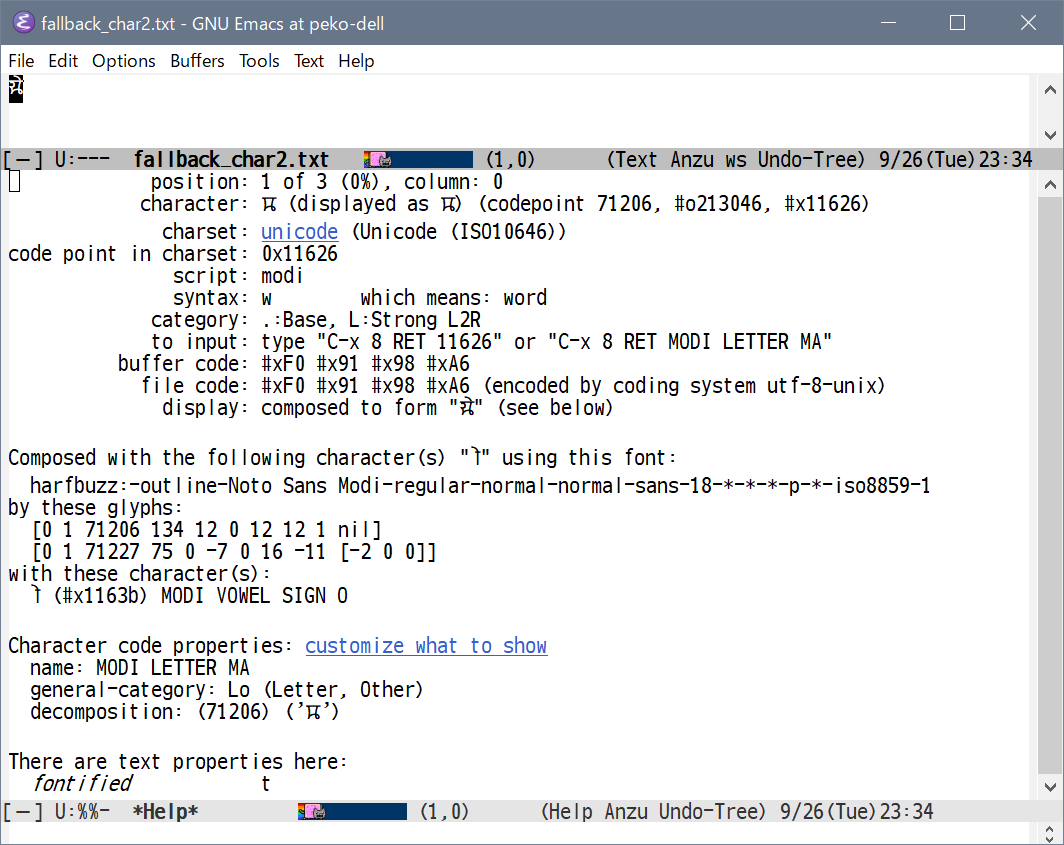
./src/emacs -Q --no-splash -fn 'Noto Sans Modi' fallback_char2.txt
テレワーク。早くもなく遅くもなく終了。
Emacsのフォントフォールバックでみつけられないフォントファミリの件。
なんとなく harfbuzzか uniscribeかに関係無い方法で表示可否を判断しているような?🤔
uniscribeで表示可能か否かを判断している為、harfbuzzならば表示可能な場合でも
表示可能なフォントをuniscribe基準で判定している(==表示できないと判断)してしまった結果、
表示できるフォント無しという事になってるんじゃないかと推測してみたり。
例えば、Modi文字(参考Wikipedia)
は harfbuzzならば表示可能なフォント「Noto Sans Modi」を指定していても
uniscribeでは表示できません。という所からの推測です。
もう少し調べてみたのですが違うかも😓
AM中に起床。
掃除したり洗濯したり。
Emacsのフォントフォールバックで時間がかかる場所。
ELISP上からフォントファミリの一覧を取得する関数font-family-listってのがあるのですが、
何故か重複しているなぁ?と思っていました。
以前、フォント設定を行うのにフォントファミリの一覧から
選択するようなELISPを作ったとき、関数delete-dupsを使って重複するリストの要素を
削除するという事をやったのですが、この時は何故重複する要素があるのかまでは調べていませんでした。
で、フォントファミリ一覧を生成する実体は src/w32font.c 内の 関数w32font_list_family() で
行なっていて、更に潜ると 関数add_font_name_to_list() が下請け関数として 得られた一つの
フォントファミリオブジェクトをリストに追加するという事をやっているようなのですが、
既にリストに含まれている要素と同じものがあれば追加しないって事をやっている風に見えます。
しかしデバッグprintを仕込んで見てみると、マルチバイト文字のフォントファミリ名の場合が
うまく動いていないようで、結果、同じ名前の要素が含まれるリストになっているようです。
試しに、関数w32font_list_family()の方は重複しないように直してみたのですが、
ELISPの 関数font-family-list の結果は様子が変わらず。なんでだ?🤔
font-family-listは組み込みELISP関数のようですが、w32font_list_family()とは別のコードで
複数のフォントドライバが返すフォントファミリ名リストを重複排除するように連結してっぽい。しかし、
「if (NILP (Fmemq (XCAR (val), tail)) && ...)」という感じで 関数memq
を使って リストの中に同じものがあるか否かを検査してっぽいのですが、
文字列の場合にこれでちゃんと動くのか?🤔と思ったりも。
memqじゃなくてmemberなら良いんじゃないか?と思って Fmember(...) に書き換えてみたのですが、
何故か反応が変わらず。なんでだ?と思ったのですが、蓄積するリストにはSYMBOL_NAME()で変換
して繋いでいるのに、Fmember()ではSYMBOL_NAME()で変換していないのが原因っぽい。
でもこの関数、プラットフォームによらず実行可能な関数のハズですが 今のままで大丈夫なのだろうか?
フォントファミリのリストの重複要素を削ると 要素数が 約1/3になる為、フォールバックで
フォントを探す処理も 1/3になりました。とは言え約20秒が約7秒って所なので フォント設定を
行なわなくても良しなに表示されるという感じではないかも😓。
もう一つ、表示可能なフォントはインストールされているけどフォールバックで見つからない
文字がある件はまだ理由が判らず。先日の「Noto Sans Modi Regular」と「Noto Sans Modi」は
どちらでも良いようです。
(set-fontset-font t 'modi "Noto Sans Modi Regular") ;どちらでも良い (set-fontset-font t 'modi "Noto Sans Modi") ;どちらでも良い
昼過ぎ起床。寝すぎ。
Emacsのフォントフォールバックで時間がかかる場所。
src/font.c の中の 関数font_list_entities()からフォントドライバに応じてフォントスペックの
リストを取得する関数を呼んでいるのですが、ここで時間がかかっている模様。
丁度この下に、
/* We put zero_vector in the font-cache to indicate that
no fonts matching SPEC were found on the system.
Failure to have this indication in the font cache can
cause severe performance degradation in some rare
cases, see bug#21028. */
テレワーク。早くもなく遅くもなく終了。
何気なく Emacsの ewwで Google検索ページを開いて日本語文字で検索したらなにやら
謎の検索結果になったり。よく見てみるとクエリ文字列が「...&ie=Shift_JIS&...」
となっていて、utf-8の文字列なのに Shift_JISと指定されてて 壊れた文字コードで検索しているという感じみたい。
この「ie=Shift_JIS」ってどこから出てくるんだ? と思ったのですが調べてみてもよく判らず🥺。
調べている過程の中で「eww-search-words」というコマンドがあるのを知りました。
こちらは「ie=UTF-8」となっている為、意図した文字列で検索が行なわれるようです。
でもどこで埋めているのかはやっぱり判らず🥺。
Google検索ページのソースを見てみると
「<input name="ie" value="Shift_JIS" type="hidden">」
というフォーム入力があり、ここで固定的にShift_JISになってっぽい。変えられるものなのかよく判らず。
w3m-modeでGoogle検索ページを開くと、buffer-coding-systemが shift_jis になってるなぁ?
と思ったり。w3m.elを調べてみると URL文字列を検査してgoogleっぽいページの場合は
「&ie=\\([^&]+\\)」で文字セットを取り出して buffer-coding-system を切り替えているみたい。
googleっぽくなければページの文字コードの buffer-coding-system になる模様。えぇ....
テレワーク。早めに終了。
Emacsのフォントフォールバックで時間がかかる場合に、どこで時間がかかっているのかを
特定していなかったので調べたり。どうやら font_find_for_lface() って関数の実行が
激烈に遅い場合があるようです。関数の実体は src/font.cに記されているようですが、
確かに4重ループを実行している箇所がありました。ここで時間がかかっているのかなぁ?
と思ったのですが、トータルループ回数は6回で、実際に時間がかかっているのは
ループの一番奥で実行されている font_list_entities() という関数のようです。
この関数の中の何に時間がかかっているのかはまだ判らず。深い...🥺
テレワーク。気持ち早めに終了。
調べ事。わからん。
テレワーク。早くもなく遅くもなく終了。
何気にVMwareのFedoraを起動しようとしたら、Bootの途中でファイルシステムが読み込めないと
いう状態になり起動できなかったり。ファイルシステムの異常を検知しているのはWindows(ホストOS)側なので、
VMのイメージが何かしら変に見えてっぽい模様。ホストOSを再起動したり、VMwareの15だったのを
17にアップデートしてみたりしたのですが状況変わらず。Fedora38に上げる前の37のバックアップ
からだと起動できたので、やっぱりVMイメージがダメになっていそう。てか なんでだよ!?🥺。
ひとまず Fedora38にアップデートして一旦完了。まだ Emacs29は落ちてきていない模様。
そしてImageMagickやGIMPで HEICフォーマットが読み込めないのも変わらず
(以前の日記)。
AM中に起床。
掃除したり。
フォールバックで見つかったフォントを得る方法。
先日の件をELISPで自動化する方法をもう少し調べてみました。少々散らかった感じではあるものの
手でやるよりは幾分マシくらいの方法を考えてみました。以下が作ってみた ELISPの関数です。
(defun my-chkfontset (&optional begpos endpos)
"リージョン範囲の文字をdescribe-charして*chkfontset*に蓄積したのち
set-fontset-fontの一覧に変換する。"
(interactive "r")
(let ((strbuf (buffer-substring-no-properties begpos endpos))
(wkbufname "*chkfontset*")
)
(with-current-buffer (get-buffer-create wkbufname)
(erase-buffer)
)
(dotimes (p (length strbuf))
(let ((chrstr (substring strbuf p (1+ p))))
(with-current-buffer (get-buffer-create wkbufname)
(insert chrstr)
))
(set-window-buffer (selected-window) wkbufname)
(with-current-buffer (get-buffer-create wkbufname)
(describe-char (1- (point)) (current-buffer))
(insert-buffer-substring-no-properties "*Help*")
)
)
(with-current-buffer (get-buffer-create wkbufname)
(shell-command-on-region
(point-min)
(point-max)
"gawk '{if(/ position:/){src=\"\";fn=\"\";}else if(/script:/){src=$2}else if(/harfbuzz:|gdi:|uniscribe:/){split($0,f,\"-\");fn=f[3];}else if(/\\[back\\]/){printf(\"(set-fontset-font t '\"'\"'%-15s \\\"%s\\\")\\n\",src,fn);}}' | sort | uniq"
)
)
))
Adlam (𞤀𞤣𞤤𞤢𞤥) 𞤅𞤢𞤤𞤢𞥄𞤥 Amharic (አማርኛ) ሠላም Arabic (العربيّة) السّلام عليكم Armenian (հայերեն) Բարև ձեզ
(set-fontset-font t 'adlam "Noto Sans Adlam") (set-fontset-font t 'arabic "Noto Sans Arabic") (set-fontset-font t 'armenian "Consolas") (set-fontset-font t 'ethiopic "Ebrima") (set-fontset-font t 'latin "") (set-fontset-font t 'latin "MeiryoKe_Console")
(set-fontset-font t 'tagalog "")
(progn (set-terminal-coding-system 'cp932-unix) (set-keyboard-coding-system 'cp932-unix) (set-buffer-file-coding-system 'cp932-unix) (setq default-process-coding-system '(cp932 . cp932)) (setq locale-coding-system 'cp932) )
AM中に起床。
フォールバックで見つかったフォントを得る方法。
良い方法とは思えないけど一応判るかな?という方法として、
(set-fontset-font t '文字セット "フォントファミリ名")
で記す。
(set-fontset-font t '(#x30edd . #x30ede) (font-spec :family "源ノ角ゴシック") nil 'append) ; ビャンビャン麺 対応
昼過ぎ起床。寝すぎ。
Emacsの文字によって表示に時間がかかる件。
とりあえず、fontset.c内の 関数 fontset_find_font() に時間計測のデバッグコードを入れてみたところ、
見た時間範囲での 関数実行自体は 3.1万回くらい実行していたのですが、
そのうち 1回の実行に 20秒ほどかかるケースが3回あり、おそらくこれが幅を利かせているようです。
3.1万回の殆どがミリ秒単位表示で 0.0msなのですが(Cygwinではclock関数の時間分解能がmsなため)、
15ms以上かかっているケースが400回ほどあり(20秒かかる3回もこれに含まれる)、
ただ単純に 15ms×400としても 6秒になってしまうので、まぁまぁ時間がかかる事には変わりはありませんが🥺。
デバッガでの実行を想定して -O0でビルドしていたのを忘れていたので -O2でビルドし直してみたのですが、
20秒かかるケースが縮んだりはしませんでした。
一応原因判明。20秒ほど時間がかかるのは 文字のフォント指定が無い為、フォントフォールバック
で探している時間でした。Emacs上の文字セットで言うと sinhala、tibetan、khmer に対応するフォントを
探すのに時間がかかっていたという感じでした。
デバッグコードを仕込んで調べた結果、フォントフォールバックで一応フォント(フォントファミリ名)が
見つかっているので、フォントセットを .emacsで指定してみたところ、M-x view-hello-file の実行が
1秒くらいになりました😅。なんてこった。参考までに今回追加したフォントセットは以下です。
(set-fontset-font t 'sinhala "Nirmala UI") (set-fontset-font t 'tibetan "Microsoft Himalaya") (set-fontset-font t 'khmer "Leelawadee UI")
テレワーク。気持ち早めに終了。
Emacsの文字によって表示に時間がかかる件。
とりあえず、fontset.c内の 関数 fontset_find_font() に当たりを付けてデバッグ表示を
仕込んだり強制的にループを脱出してみたりして反応を見たり。
何かしら時間がかかって待たされているようにも見える場合があるようですが、
具体的にどこで時間がかかっているかは判らず。
テレワーク。気持ち早めに終了。
Emacsの M-x view-hello-file で各国言語の挨拶テキストが表示できますが、
フォントのインストールや設定をうまく行なわないと表示されない文字が出てきます。
我が家の設定では一応全ての文字は表示できるものの表示されるまでに猛烈に時間がかかります。
よく判らないけどこんなものなのか?とも思っていたのですが、
高々画面上に表示された文字数の文字を表示する事を考えると時間がかかり過ぎじゃないか?
と思ったりも。という訳で何に時間がかかっているのか調べようとしているのですが当たりが付かず。
テレワーク。早めに終了。
調べ事して終了。
テレワーク。気持ち早めに終了。
Web巡回して終了。
テレワーク。早めに終了。
「Emacsの雑記」の中に、
ImageMagickのconvertコマンドを拡張する wrapped_convertというスクリプトを置いてあるつもりだったのですが、
アップロードし忘れていたというのに今日気づきました😓。
去年、Emacs-28.1ベースに更新した時からずっと Not Foundに
なっていたと思います。役に立たない状態になっててすみませんでした。
AM中に起床。
掃除したり洗濯したり。
そういやノートPCのEmacsで文字入力をしていて、変換キーを押していないのに候補が出てくるなぁ?
と思ったり。調べてみたところ、普段使いのデスクトップPCでは MS-IMEの予測入力がOFFに
なっていて、そのため変換キーを押さないと変換候補が出てこないという感じになっていました。
なぜOFFにしたのか記憶に無いのですが、予測入力の候補は気に入らなければその場で「×」を押して
誤変換候補を削除できるので、まぁ ONで良いかと思ったりも。
なるだけ長い文を変換した方が良いというのは判ってはいるものの、直ぐに単語で区切ってしまいます😓。
以前の書き込みを見返していて、
ローマ字入力中でも「半角/全角」キーが効くっていうのを すっかり記憶から消し去っていました😓。
ローマ字入力で「ビルドにmakeとautoconfを使用します」みたいなのを入れようと思うと、
前述「半角/全角」キーを使わないと、「autoconfを」は文節を調節しても
「autoconふぉ」か「autoconfwo」にしか変換できません🥺
AM中に起床。
Cygwinパッケージを更新。minttyのアップデートが含まれていました。
前のバージョンで
minttyに表示された文字列をマウスのダブルクリックで選択したときに「~(チルダ)」が選択の対象にならなくなって
いました(以前のメモ)。
今回のアップデートで直った(バグ修正したのか仕様的に元に戻したのかは判りません)ようです。
ともかく 「~/pathto/filename.ext」が、いちいち「/pathto/filename.ext」になって
そんなファイルは無いって怒られるストレスから解放されそうです。
テレワーク。早めに終了。
夕方以降 大雨のニュースばかりになっているのですが、台風の本体は無くなったのか?
明日付けになっていますが
「Emacsの雑記」を更新しました。
先週から対応&テストしていた
IMEパッチでインライン変換時の表示フォントサイズを text-scaleに連動させる件を追加しました。
御参考まで。
テレワーク。早めに終了。
org-modeのエクスポート時にzero width space(ZWSP) を削って出力する機能。
Emacs-29.1の lisp/org/ox.el 向けですがパッチにしてみました
(org-mode_zwsp_patch_230907.patch)。
以下の様な ZWSPを使ってorg表記をコントロールした例(以下はZWSP文字が含まれています)。
例えば 日本語文字列の間に続けて「=」や「*」を入れても装飾文字と認識されないので、
ZWSPを使って区切りを明示する必要があります。ZWSPを使わないのであれば 半角空白文字を
区切りに使う事になりますが、HTMLに出力すると空白文字が1文字入ってしまう事になります。
#+STARTUP: showall
#+TITLE: Org-mode ZWSP export control test
#+OPTIONS: ^:{} toc:nil timestamp:nil -:nil creator:nil author:nil zwsp:nil
* Zero Width Space のエクスポート抑止テスト
「#+OPTIONS:」の「zwsp:nil」で「Zero Width Space」のエクスポートを抑止できます。
- =今日=は*良い*_天気_ですね🙂
- <<識別文字列>>「<<識別文字列>>」と書くと
- [[識別文字列][[[識別文字列]]]]で文書内リンクになります。
<ul class="org-ul"> <li><code>今日</code>は<b>良い</b><span class="underline">天気</span>ですね🙂</li> <li><a id="org7dbc6ee"></a>「<<識別文字列>>」と書くと</li> <li><a href="#org7dbc6ee">[[識別文字列]]</a>で文書内リンクになります。</li> </ul>
今日は良い天気ですね🙂
テレワーク。気持ち早めに終了。
実験。org-modeのexportに zero width space(ZWSP) を削って出力する機能を付けてみようと思い試していました。
削るのは単純な文字列置換で行うようにしたのですが、「#+OPTIONS: 」にキーワードを追加して
ON/OFFできるようにしようとしたところ、どこにどう入れればスイッチの状態を取得できるのかよく判らなかったり。
org/ox.elに 変数org-export-options-alist というのがあり、「#+OPTIONS: 」で指定できる
キーワードが並んでいたのでここに足せば良いのかと思ったのですが、足しただけでは何も起こらず。
むーん?🤔
もう少しよく見てみたら、エクスポートデータを生成する関数内であれば追加したスイッチの状態を
取得できる事が判りました。生成されたデータを加工する感じで実験していたのですが、
データを生成する関数の最後の方で加工する事になる為 どのような形式でも有効になるのが
良いかもと思ったり。という訳で思った感じになった気も。
テレワーク。気持ち早めに終了。
実験。なんかうまく反応せず🤔
テレワーク。早めに終了。
Org文書内の任意の位置にリンクを張る方法が無いか?と思ったり。
「4.2 Internal Links」という方法が
そのものズバリな方法でした「<<target>>」という感じで記すと、
HTMLにエクスポートした時には見えないタグが埋め込まれて、「「[[target][なんとか]]」で
リンクによる参照が可能になるという仕組みのようです。
org-modeの文法では 文書にまぎれて特殊な操作を行うコマンドなどを記述しますが、
それ自身をエスケープする方法が用意されていなくて
以前知った「zero width space(ZWSP)」を
使ってコマンドと解釈されないようにするのがお勧めとされています。
しかし、HTMLエクスポートした時にも ZWSPがそのまま出力されるので
ブラウザで表示されたものをコピペすると ZWSPが邪魔になる場合があります。
HTML化した後に ZWSPを削除するようなモードって無いのかなぁ?🤔 と思い調べてみると、世の中では
パッチ
は提案されているっぽいですが 取り込まれてはいなさげ?
AM中に起床。
掃除したり洗濯したり。
Makefileやプログラミング言語の中には「\」(ASCII文字の0x5c)を行の継続記号として使用するものがあります。
長い式やリストの場合に改行を入れてしまうとそこで切れてしまうため、編集しやすくしたり読みやすくする為に
行の継続記号を使用する感じかと思います。
一方 TeXや Emacsの org-modeでは「\\」を明示的な改行記号として使用します。基本的に改行を入れても
存在しないものとして長い行として解釈されるような場合に、改行として明示的に区切る為に使用する感じかと思います。
どちらも「\」を使うのでどっちの意味だっけ?というのを忘れそうになるのですが、先に記したように
改行が区切りを示すものか 無視されるものかで それを打ち消す方向で使うって考えれば良いかなと思ったり。
先日、普段使いのEmacsのテーマをダーク系に変えたのですが、
org-modeの HTMLエクスポートを行なった際、SRCブロックの色がダーク系テーマのfaceでエクスポートされます。
Web表示の背景色がライト系の想定だと、文字色が明るすぎて読みづらい感じになってしまいます。
文書を書いている最中は色は気にしないとして、
最後の仕上げ出力の時は Emacsのテーマをデフォルトに変更してからエクスポートする必要があります。
地味に面倒くさいかも😓。
AM中に起床。
IMEパッチでのインライン変換表示のフォント。
インクリメンタルサーチ時の条件が足りてないなぁというのに気づき直してみたり。
設定との合わせ技での対応なのでちょっとイマイチな感じもしたのですが、
設定すれば良い(元々設定してねって事にしてある)ので まぁいいかって事にしよう😅。
Emacs 29のブランチを見ていると、29.1がリリースされた後の変更量が結構多いなぁと思ったりも。
30系をいつリリースするのかは判りませんが、29.2を出してから30系の計画が出るのだとすると、
30系ブランチにマージされたAndroid対応は忘れた頃に出る感じになるような気も。
個人的には 29.2を今年の秋頃に出して、30系は2024年春頃をリリース目標にするくらいだと良いなぁと思います。
フィーチャーFIXしてから29.1が出るまでの期間は 大量のtree-sitter関連バグ修正を行なっていたので、
結局のところ出すって決まらないと整わないのだろうと思われます。
そういえば、テキストエディタの vimの読み方。
Wikipediaに
「ぶいあいえむ」と読むのは誤りとあるのですが、昔(90年代)からそうなんだっけ?と思ったり。
Wikipediaにある runtime/doc/intro.txt の履歴をvimの gitリポジトリをcloneして調べて
みたところ、intro.txtに発音についての文言
「Vim is pronounced as one word, like Jim, not vi-ai-em. It's written with a capital, since it's a name, again like Jim.」
が足されたのは 2010年1月6日のコミットのようです。という訳で2010年以降は「びむ」かも知れませんが
それ以前がどうだったかは判らず。
Google検索で 期間を 2009年12月31日以前にして検索してみたのですが、読み方に触れたページは見つけられず。
ただし Web上のデータは消滅する可能性がある(最初から存在していないのではなく 存在していたけど無くなった)
ので歴史探索は意外と難しいです。
英単語として vim は「活力」とか「元気」って意味があるらしいですが それは「びむ」って発音するみたい。
個人的には「びむ」って読み方をしているのを音声で初めて聞いたのは 2018年くらいで、
その時に読み方もそれが正式だって知ったのですが、viは初めて知った時(1993年頃)から
「ぶいあい」って言われたのと、vimはその流れで「ぶいあいえむ」って言ってた(1994年頃)ので、
個人的には「びむ」って読み方の方に違和感があります😅。
テレワーク。早めに終了。
Web巡回して終了。