2023/10/31
テレワーク。早くもなく遅くもなく終了。
「﷽」の表示。
ScriptItemize()というAPIを実行して得られた SCRIPT_ITEM という構造体のメンバーに含まれる
SCRIPT_ANALYSIS という構造体の フラグメンバー変数fRTLをtrueにした上で
ScriptShape()を実行すると、これまで一つしか得られなかったグリフコードが5つ得られるようになりました。
ただ、ScriptTextOut()では何か間違っているのかうまくレンダリングできていません。
そこで試しに 得られた「0xddf, 0xdde, 0xddd, 0xddc, 0xdbb」の5つのグリフコードを
ExtTextOutW()のETO_GLYPH_INDEXモードを使ってレンダリングしてみたところ、
ブラウザ表示のような横長の「﷽」文字が表示されました。
グリフの列さえ得られれば ExtTextOutW() でイケるようなので、Unicodeのコードポイントからグリフコードに
変換する所をどうにかすればどうにかなるんじゃないか?と思ったりも。まだ上手くいくか判りませんが。
2023/10/30
テレワーク。気持ち早めに終了。
調べ事をして終了。
2023/10/29
AM中に起床。
掃除したり洗濯したり。
Pouetで最近行なわれたパーティーでの作品動画を観ていて
「日本っぽいなぁ?」と思うものがあったのですが、
「TDF 16ms #0」という「Tokyo Demo Fest」の系譜に
あたるオンライン デモパーティーが開催されていたようです
(Pouetの結果)。
ほぅ....。
因みに wild demoに 来年開催が予定されている「68k inside 2024」の
アナウンスのデモムービーが登録されてますが X68kで動くデモでした
(68k inside 2024 announcement by AFWD)。
X68kで動くデモは .XDF 形式を含むアーカイブが登録されていて エミュレータでも動作するみたい。
ただし、68k inside 2024 自体は モトローラの68000系CPU を搭載したマシン全般を対象にしていて、
開催はフィンランドのヘルシンキで行なわれる予定のようです。
「﷽」の表示。
uniscribeを使うという方法を試してみたり。ScriptShape()、ScriptPlace()、ScriptTextOut()を
使って 文字列→グリフ→レンダリング という流れになるようなのですが、
グリフをExtTextOutW()のETO_GLYPH_INDEXモードを使ってレンダリングするのと変わらない
(先頭の部分文字しか描かれない)感じだったり。
ExtTextOutW()の非ETO_GLYPH_INDEXモードやDrawTextEx()と同じ結果を得るにはどうすりゃいいんだ?🤔
2023/10/28
昼頃起床。寝すぎ。
「﷽」の表示。
そういやEmacs上のどこで文字をグリフコードに変換しているのだろう?と思って調べて
いたところ、composition-get-gstringという組み込みELISP関数があるというのを知りました。
使い方をちゃんと把握できていないのですが、scratchバッファで実行してみたところ
以下のような感じで結果が得られるようです。
(composition-get-gstring 0 1 (font-at 0 nil "﷽") "﷽") ;;and press C-j
[[#<font-object "-outline-Tahoma-regular-normal-normal-sans-25-*-*-*-p-*-iso8859-1"> 65021] nil [0 0 65021 3515 38 -1 38 17 4 nil] nil nil nil nil nil nil nil]
ブラウザ表示すると見た目が合わないのですが、結果としては
「[HEADER ID GLYPH ...]」というフォーマットになっているようで、上記例だと
HEADERは「[#<font-object "-outline-Tahoma-regular-normal-normal-sans-25-*-*-*-p-*-iso8859-1"> 65021]」、
IDは「nil」、GLYPHは「[0 0 65021 3515 38 -1 38 17 4 nil]」 って感じなのかな?と思われます。
後ろに nilが7個続いているのですが、これは何なのかはよく判っていません
(composition-get-gstringのヘルプには無視しろと記されてます)。
GLYPHのフォーマットは
「[ FROM-IDX TO-IDX C CODE WIDTH LBEARING RBEARING ASCENT DESCENT [ [X-OFF Y-OFF WADJUST] | nil] ]」
となっているようで、
3要素目「65021(#xfdfd)」は﷽のコードポイント、4要素目「3515==0xdbb」がグリフコード、
5~9要素目は表示領域に関する情報 という感じに並んでっぽい。
Tahomaの場合のグリフコードが0xdbbというのは、前にデバッグコードを仕込んで
調べた値と同じなので、見掛け上composition-get-gstringの結果を覚えておけば
グリフコードから元のコードポイントに復元可能という感じではあるのかも。
ただ、やっぱり 1つのグリフ情報しか含まれていないようなので、
前にGDIで調べた感じの通り、複数のグリフで構成されている可能性があったとしても、
今調べている範囲では 複数のグリフが存在しているようには見えません🤔。
2023/10/27
テレワーク。早くもなく遅くもなく終了。
調べ事。やっぱりよく判らない。
2023/10/26
テレワーク。早くもなく遅くもなく終了。
調べ事をして終了。
2023/10/25
テレワーク。早くもなく遅くもなく終了。
Web巡回して終了。
2023/10/24
テレワーク。気持ち早めに終了。
JIS90の字形。そういやX68kを使っていた時ってどんな字形だったっけ?と思い、
エミュレーターを起動して調べてみました。
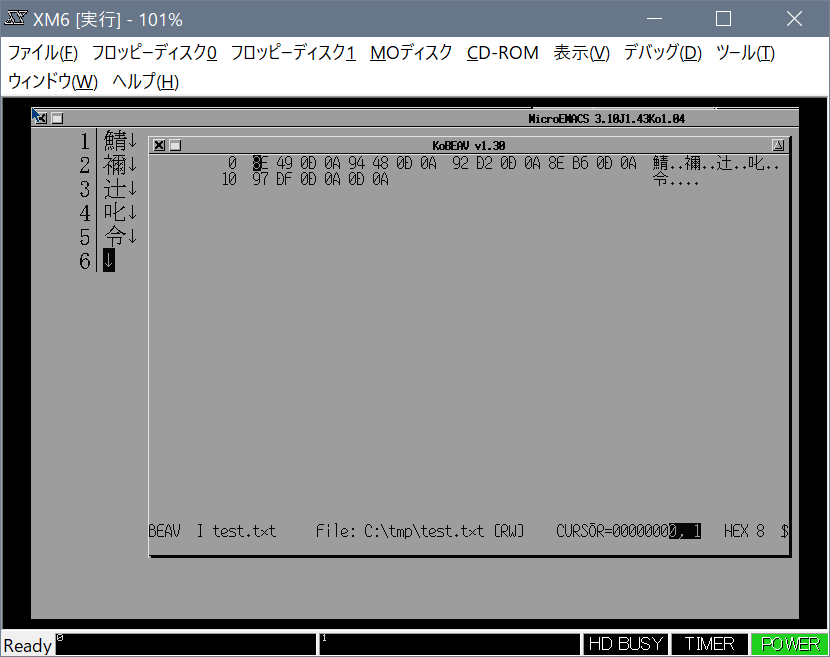
Ko-Windowで koem(後ろのウインドウ)と kobeav(手前のウインドウ)で表示しています。
koemでの表示は24ドットフォントですが、アンチエリアス無しだとこんなでしたっけ?
って感じです。さておき、鯖、禰、辻 は(当たり前ですが)いずれもJIS90の字形になっています。
𠮟(口に七)は無いので叱(口にヒ)となります。明朝体なので令は今と変わらずな感じだったようです。
2023/10/23
テレワーク。早くもなく遅くもなく終了。
令和の「令」の字形。
こういう話
があったらしい。明朝体ってレタリング上の 一デザインだよね?とも思ったのですが、
こちらのように
明朝体テイストを含んだ手書き文字だったが故に いちいち正解を求められていたもよう。
そして楷書体フォントでもそういう対応をした製品があるみたい
(参考サイト)。
逆に、もしこれが「点にマ」で書かれていたとしたら「明朝体には同じ文字が無い」って
なっていたのだろうか?
2023/10/22
昼頃起床。寝すぎ。
掃除したり洗濯したり。
異体字セレクタ。以前鬼滅の刃の「ねずこ」の漢字は
正式には「襧豆子」だというのを知ったのですが、Shift-JIS(CP932)では「禰豆子」が
充てられているのを知りました。「襧」はUnicodeでは #x8967なのですが、
ブラウザやEmacsではこの文字だけ別のフォントで表示される感じになります。
今日Webを散策していて、Windows10の標準フォント(MSゴシック、メイリオ、BIZ UDゴシック、游ゴシック など)
で異体字セレクタを使用すれば表示可能だと知りました。
- 禰(U+79b0)
- 襧(U+8967)
- 禰󠄀(U+79b0;U+e0100) U+e0100は VARIATION SELECTOR-17
異体字セレクタを使用すると書体が揃う(フォントファミリが同じなので当たり前かも知れませんが)
のが良いと思います。
上記表示では U+e0100 を直接入力していますが、HTMLであれば
「禰󠄀」と書けば「禰󠄀」と表示されるようです。
フォントが対応しているか否かに依存する事になってしまいますが、少なくとも現在のWindows10以降で
フォントをカスタム選択していなければ、良しなに表示されるんじゃないかと思われます。
異体字セレクタを使用すると表示が揃うとか「禰」でも検索できるなどの利点はありそうですが、
プログラムの方で対応しないとうまく扱えないケースがあるようで、一長一短ありそうです。
あまりよく見ていなかったのですが、「襧(U+8967)」は「ころもへん」ですが、
「禰󠄀(U+79b0;U+e0100)」は「しめすへん」だな?どうやら 「しめすへん」の方が正解だったらしい😓。
因みに、我が家の Emacsでは MeiryoKe_Consoleを常用していますが切り替わりませんでした。
もしやと思い Windows11のノートPCで試したところ イケました。どうやら新しいMeiryoKeではイケるのかもと思い、
Windows10対応で最新の 6.50rev2というのを試してみたら、Windows10の Emacsでも
「禰󠄀(U+79b0;U+e0100)」の表示がイケるようになりました。
しかしながら、漢字を異体字セレクタで切り替える目的は
こちらのページ
にあるような、JIS2004の字形ではなく 古いJIS90の字形で記したい場合に使うという感じのようにも思えます。
なので「通常は使わないもの」と考えた方が良いのかも知れません。
魚の「サバ」は「魚へんに青」と覚えていたのが、JIS2004では「鯖」になっていて、
魚へんに青の「鯖󠄀(U+9bd6;U+e0100)」はJIS90の字形なので異体字セレクタを使わないと出せないという
感じみたい。歴史的には「鯖」の方が古い漢字で、略字として「鯖󠄀」の方が新字体になったけど、
やっぱり正しい漢字を使う方向に改定されて「鯖」の字形の方が新しいって事になっているらしい。
旧字体の方が字形としては新しいってのは 訳が判らない事になっているとは思います。
ただ、異体字セレクタを使うのは 入力も表示も含めて単純に「面倒くさい」ので、
「現在の正しい漢字を使ってください」という流れで いずれ異体字は自然に使わなくなっていくのかも?
と思ったりも。
2023/10/21
昼頃起床。寝すぎ。
Webを散策していて
「Emoji 最新版の様相」
というページの存在を知りました。
VS-16(Variation Selector-16)の役割が判ったというのと、
これまでに なんか謎に思っていた事
(以前のメモ1,
以前のメモ2,
以前のメモ3)の理屈が判ったように思います。
あと、Emacsの 関数set-fontset-font の第二引数指定する 文字の範囲のシンボルに
「'symbol」と「'emoji」があって、何がどう違うのかよく判っていませんでしたが
使い分ける理由が判ったような気も。
まず、「元々カラーでは無い絵文字として昔から存在している文字」と
「最初からカラー絵文字として存在している文字」の違いがあるという前提を知っておく必要が
あると理解しました。
これを踏まえて以前のメモ1がどういう事だったのかを
再度解釈してみますに、
- 「☀(#x2600)」は元々カラーでは無い絵文字だった
→モノクロ表示可能なフォントと カラー絵文字フォントのどちらでも表示可能 だけどどっちにする?
の結果、表示の互換を維持する選択をしたので カラー絵文字を選びたければVS-16を使用するという事に
なったと想像しました。
ここでややこしいのは「Chromium系ブラウザ」では VS-16を付加しても反応しない場合があるという所。
「☀:VS-16無し」と「☀️:VS-16有り」は表示が切り替わらないけど、
「🌶:VS-16無し」と「🌶️:VS-16有り」は表示が切り替わります。
TANEはここで訳が分からなくなってました。
ただ、「☀(#x2600)」は「BLACK SUN WITH RAYS」という名前の文字なので、
VS-16を付けてカラー絵文字になると名前通りの文字にならないという矛盾が生じる点は
Unicodeの仕様がバグっていると思わなくもありません。
理屈は判った気がしますが、表示互換を維持するならばVS-16を使う方法ではなくて、
元々あった文字のコードポイントとは全く別なコードポイントにカラー版として定義すべきだった
のではないかと思います。なぜなら、元々の文字は表示できるフォントが既に存在している訳だし、
カラー化するにしても新しいデザインの文字を用意し直す必要があるのには変わりありません。
入力するのもこれまでの文字か 新しいカラー文字かを 選ぶ必要があるのは変わらない、
カラーか否かを判断するのもいちいちVS-16の有無を見なくてはならなくて
処理も面倒臭いように思いますし、「BLACK SUN WITH RAYS」のような迂闊に付けた名前を
リセットできるとも思います。
「古いシステムで新しい文字のコードを表示したら豆腐になる」....それは別に良いんじゃないか?
現状、MS-IMEではVS-16が埋められる事は無いので「❤(#x2764):HEAVY BLACK HEART」は
変換候補表示ではカラー表示となっていますが、Emacsでは確定するとカラーにはなりません。
Emacsであれば「❤」を入れた後に「C-x 8 RET」で fe0f(VS-16のコード)を追加すれば
「❤️(VS-16有り)」に修正できますが、Chromium系ブラウザでは反応しません。
「だって、HEAVY BLACK HEART って文字なんでしょ?」と言われるとぐうの音も出ません。
という訳でやっぱり絵文字は闇が深いと感じます🥺
ところで「☀」を「BLACK SUN WITH RAYS」としたり「☹」を「WHITE FROWNING FACE」と
したのは何故なんだ?と思ったりも。Emacsをダーク系テーマに切り替えてから、
なおさら「色なんて限定できないだろ?」と感じるようになりました😓
2023/10/20
テレワーク。気持ち早めに終了。
Emacs 29.1.90。29.1向けのIME/他パッチを当ててビルドしてみたり。
特にリジェクトされる事も無くビルドも完了。
ちょろっと立ち上げてみた感じ、いきなりズッコケたりする事は無さげ。
アーカイブソースを比較してみた感じ、ドキュメントの変更量は多い気がしますが
機能的な変更はあまり無いような気も。
2023/10/19
テレワーク。早くもなく遅くもなく終了。
「﷽」の表示。Emacsのソースコードの中で SetTextAlign() を使用しているのか?と思い
grepしてみたところ、src/w32term.c の中でいくつか使用しているようですが、
左寄せ表示するのに使っているだけのようです。
Emacsでは ExtTextOutW()で文字をレンダリングする際に グリフインデックスを使用するモードで
描画しています。Emacsと同じように描画してみた上で、SetTextAlign(hdc,TA_RTLREADING)を事前に
実行してみたのですが、やっぱり 先頭の部分だけしか描画されないようです。

フォントがTahomaの場合、グリフコードは 0xdbb のようで、その前後の 0xdba と 0xdbc も
一緒にして、「0xdba,0xdbb,0xdbc」を描画したのが画像の左上の赤背景の文字列です。
右下のが DrawTextEx()でDT_RTLREADINGありで描画したもので、それと見比べると
正解文字列の行頭部分(アラビア文字なので右が行頭、左が行末)だけの描画になっています。
結局、SetTextAlign(hdc,TA_RTLREADING)を事前に設定したところで
グリフインデックスを使用するモードだと 一つの部分文字しか描画されないので並びの設定
以前の問題か?とも思ったり。
ところで、一旦 グリフコードになってしまうと元のUnicodeのコードポイントに戻せないので、
「﷽」の場合は特別な処理を発動させて対応しようにも無理だなぁ?🤔
おや?Emacs 29.1.90がリリースされてるなぁ?
(Emacs 29.1.90 pretest is available)。
以前、秋ごろに 29.2が出ると良いなぁ?
くらいに思っていたのですが、今の感じだと年内に29.2で一回刻むってところかしら?判りませんけど。
2023/10/18
テレワーク。気持ち早めに終了。
「﷽」の表示。どうやら、アラビア語のような右から左に向かって書く文字の場合は
「SetTextAlign(hdc,TA_RTLREADING)」で設定しないとダメらしい。

上の赤背景の描画が「SetTextAlign(hdc,TA_RTLREADING);」した後 ExtTextOutW()で描画したもので これが多分正解。
左下の赤背景の描画が「SetTextAlign(hdc,0);」した後 ExtTextOutW()で描画したもので、
これは Emacsで Tahomaを使った場合に「見切れている」と表現していた描画と同じに見えます。
右下の青背景の描画は DrawTextEx()で描画したものです。
こちらも SetTextAlign()の設定影響を受けるようです(引数dwDTFormatでオバーライドできるっぽい)が、
ExtTextOutW()と違って見切れる事は無く描画できるようです。
ただし、スナップショットでは「SetTextAlign(hdc,0);」が効いている為、見切れないけど並びが逆になってしまうようです。
先日のスタティックコントロールと同じ描画と思われます。
という訳で、原因はなんとなく見えてきたけどどのように対応するのが正解かはよく判らず。
2023/10/17
テレワーク。気持ち早めに終了。
「﷽」の表示。Win32APIの スタティックコントロールでフォントを指定して表示してみたところ、
横に長い文字でレンダリングされるようです。Emacsとの違いは glyphcodeで描画しているか否か
くらいのような気もするのですが? スタティックコントロールなのでフォントの変更くらい
しかできないので、もう少しGDIのテキスト文字描画APIを使って様子を見てみるか....

ところで先日調べた感じだと、EdgeブラウザではTahomaで
描画されているんじゃないか?と思われるのですが、スタティックコントロールで描画
したTahomaの描画は 左右の並びが逆になっているような気がしたりも?一文字を表示しているのかと
思ったのですが、内部的にはいくつかの文字に分割されているって事?
そして何かしら設定が足りなくて並びが逆になっている?🤔。
という点を踏まえてEmacsでの描画を見てみると、見切れているのではなくて
いくつか並ぶグリフの一つ分だけ描画して終わっている感じに見えなくもないように思えたりも。
2023/10/16
テレワーク。早くもなく遅くもなく終了。
「﷽」の表示。やっぱりGetGlyphOutlineW()が見切れた領域を返しているように見えます。
なんでだ....?
2023/10/15
昼過ぎ起床。寝すぎ。
掃除したり洗濯したり。
以前知った「﷽」という文字。
Edgeなどのブラウザでは表示されますがどのフォントを使って表示しているのかがイマイチ判りませんでした。
InkscapeやGIMPの文字ツールから察するに、多分「Tahoma」で表示されているのではないかと推測しました。
他にも「Arial」や「Microsoft Sans Serif」や「Segoe UI」でも表示できるようです。
「Segoe UI」は小さい描画領域で表示できるようにデザインされたもののようなのでちょっと毛色が違いますが。
Emacsで fontsetを指定して様子を見てみた感じ、「Tahoma」や「Arial」などでは途中で見切れているようにも思えました。
そういやと思い emacs-gtk だとどのフォントを使ってどのように表示されるか見てみたところ
「Tahoma」を使って表示しているようですが、見切れ方は emacs-w32と同じになるようです。
デバッグコードを仕込んで観察してみたり。どうやら src/w32font.c内の 関数compute_metrics()で
文字の幅を得ているようなのですが、Win32APIの GetGlyphOutlineW() で得ているようで、
その結果が見切れた幅で返っているっぽい。あれ? これじゃ やりようが無いなぁ...?🤔
「./src/emacs -Q -fn 'Tahoma'」でフォントを指定して起動しても見切れるのでなんかダメな気が。
Windows10のメモ帳で﷽を表示してみたところ、こちらは横長の文字で表示される模様。
多分Arialで表示されてっぽい。フォントはともかく DirectWriteでの描画では無いハズなので、
Emacsでも同じようにレンダリングできて良さそうなのですが....?
2023/10/14
昼前起床。
何気に Emacsの artist-modeで絵文字とかUnicode文字って使えるのだっけ?と思い
ちょろっと試してみたのですがダメそう。
Windows11のノートPCのWindowsUpdateを実行したとき、先週の「👶:BABY」を含めた
家族絵文字をEdgeで表示したのですが、ひっついていないなぁ?と思ったり。
先週時点では Windows10の Segoe UI Emoji だけで確認していて、Windows11のでは見ていなかったのですが
引っ付かなかったとは。やっぱ絵文字ムズい🥺。
2023/10/13
テレワーク。早くもなく遅くもなく終了。
Web散策して終了。
2023/10/12
テレワーク。早くもなく遅くもなく終了。
そういや、最近買った本に「RFタグ」なるものが挟まっていたのですが、なんぞこれ?と思ったり。
Web検索してみるとこういう記事を
見つけたり。ほぅ...。全部の本に挟まれるようになれば リーダーを持って歩くだけで
リアルタイムに在庫状況が判る日が来るのかしら?
「16bitセンセーション ANOTHER LAYER」ってアニメ(公式)。
タイムスリップ先が 1992年の12月設定だと確かにこうかと思ったりも。
1992年と言えば Windowsは3.0時代だし 日本ではパソコンと言えばNECのPC-9801の事を指していて、
インターネットもまだ一般には普及していなくて、パソコンを持ってるとか使っているという人は
かなり少なかったように思います。ただ、秋葉原の街中に居るとパソコンを扱うのが普通の事のように
錯覚していたかも知れませんが😅。
という事を踏まえると、1992年時点で13歳以上くらいじゃないとなんの事やら判らないという気がします。
いや、そういう層がターゲットなのだろうとは思いますが。
2023/10/11
テレワーク。早くもなく遅くもなく終了。
WindowsUpdateでEmacsを終了したついでに、
Emacs 29.1の admin/unidata/emoji-zwj-sequences.txt を gitの最新(Unicode 15.1対応)版に入れ替え、
ここ1週間くらいで判った 増やせそうな絵文字の合字パターンを追加したものを普段使いしてみる事に。
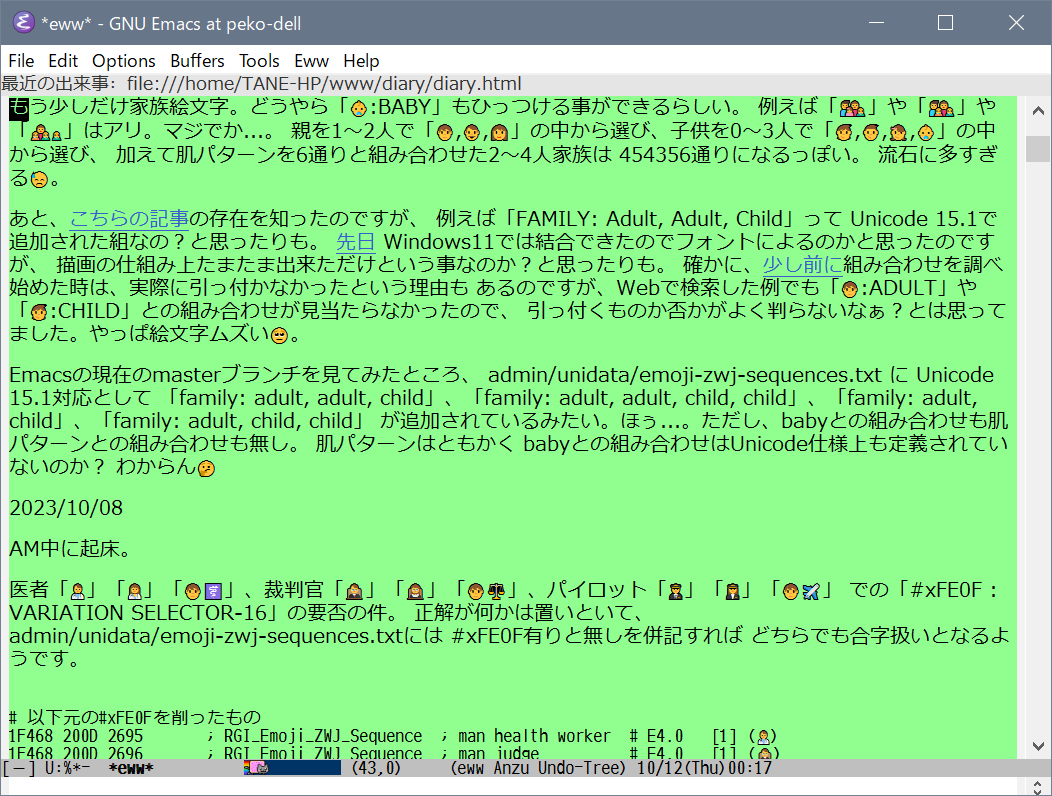
ブラウザではイケてたけど Emacsではイケてなかった絵文字がちょっとだけイケるようになった気も。
本当にちょっとだけですが😅。
2023/10/10
テレワーク。早くもなく遅くもなく終了。
何気に以下の様なC言語のソースコードをコンパイル&実行してみたら Segfaultにならなくて
そういうもんなんだっけ?と思ったり。
$ cat null_printf.c
#include <stdlib.h>
#include <stdio.h>
int main()
{
char* nullstr = NULL;
printf("---%s+++\n",nullstr);
return 0;
}
$ gcc -O2 null_printf.c
$ ./a
---(null)+++
この方が良いのかどうかは微妙な気も。例えば malloc()した後にfree()した場合とかは
NULLポインタになっている訳では無いので ゴミを表示したり最悪Segfaultになるだろうし、
NULLポインタをprintf()してしまうようなケースは いきなり間違えている感じだと
思われるのでむしろSegfaultでズッコケた方が判りやすいとは思ったりも。
2023/10/09
昼頃起床。寝すぎ。
掃除したり洗濯したり。
もう少しだけ家族絵文字。どうやら「👶:BABY」もひっつける事ができるらしい。
例えば「👨👩👧👶」や「👨👩👶👶」や「👩👶👶👶」はアリ。マジでか...。
親を1~2人で「🧑,👨,👩」の中から選び、子供を0~3人で「🧒,👦,👧,👶」の中から選び、
加えて肌パターンを6通りと組み合わせた2~4人家族は 454356通りになるっぽい。
流石に多すぎる😓。
あと、こちらの記事の存在を知ったのですが、
例えば「FAMILY: Adult, Adult, Child」って Unicode 15.1で追加された組なの?と思ったりも。
先日 Windows11では結合できたのでフォントによるのかと思ったのですが、
描画の仕組み上たまたま出来ただけという事なのか?と思ったりも。
確かに、少し前に組み合わせを調べ始めた時は、実際に引っ付かなかったという理由も
あるのですが、Webで検索した例でも「🧑:ADULT」や「🧒:CHILD」との組み合わせが見当たらなかったので、
引っ付くものか否かがよく判らないなぁ?とは思ってました。やっぱ絵文字ムズい🥺。
Emacsの現在のmasterブランチを見てみたところ、 admin/unidata/emoji-zwj-sequences.txt に Unicode 15.1対応として
「family: adult, adult, child」、「family: adult, adult, child, child」、「family: adult, child」、「family: adult, child, child」
が追加されているみたい。ほぅ...。ただし、babyとの組み合わせも肌パターンとの組み合わせも無し。
肌パターンはともかく babyとの組み合わせはUnicode仕様上も定義されていないのか? わからん🤔
2023/10/08
AM中に起床。
医者「👨⚕」「👩⚕」「🧑⚕」、裁判官「👨⚖」「👩⚖」「🧑⚖」、パイロット「👨✈」「👩✈」「🧑✈」
での「#xFE0F : VARIATION SELECTOR-16」の要否の件。
正解が何かは置いといて、admin/unidata/emoji-zwj-sequences.txtには #xFE0F有りと無しを併記すれば
どちらでも合字扱いとなるようです。
# 以下元の#xFE0Fを削ったもの
1F468 200D 2695 ; RGI_Emoji_ZWJ_Sequence ; man health worker # E4.0 [1] (👨⚕)
1F468 200D 2696 ; RGI_Emoji_ZWJ_Sequence ; man judge # E4.0 [1] (👨⚖)
1F468 200D 2708 ; RGI_Emoji_ZWJ_Sequence ; man pilot # E4.0 [1] (👨✈)
# 以下元のFE0F有り
1F468 200D 2695 FE0F ; RGI_Emoji_ZWJ_Sequence ; man health worker # E4.0 [1] (👨⚕️)
1F468 200D 2696 FE0F ; RGI_Emoji_ZWJ_Sequence ; man judge # E4.0 [1] (👨⚖️)
1F468 200D 2708 FE0F ; RGI_Emoji_ZWJ_Sequence ; man pilot # E4.0 [1] (👨✈️)
上記例では「男性で肌パターン指定無し」の分だけですが、性別と肌パターンの組み合わせが
全部で54通り書かれているので、それと同じ分だけ #xFE0Fを削ったパターンを併記する感じです。
ところで、Emacsが合字として認識していないのか、フォントとして合字表示ができないのかの区別について。
合字として認識していない場合はauto-composition-modeがtであっても ZWJ や VARIATION SELECTOR-16 にカーソルが乗ります。
合字として認識しているがフォントとして表示できない場合は 1文字扱いになるという違いがあるようです。
例えば「🐻❄️、🐦⬛」を Segoe UI Emoji で表示した場合、Emacsでも"カーソル表示上は"1文字扱いとなります
(C-dで1文字削除するとZWJの前の文字だけが削除されるので扱いがややこしいですが...) 。
そういえばと思い、Emacs29で追加された「M-x emoji-list」での入力ってどうなるんだっけ?
と確認してみたり。今まで気づいていなかったのですが、roleやfamilyの中から選択すると
更に性別や色バリエーションの候補が出てきました。因みに件の「医者、裁判官、パイロット」を選択すると
「#xFE0F : VARIATION SELECTOR-16」付きで挿入されるようです。
Emacsに閉じた範囲では「#xFE0F」が付いたり付かなかったりという矛盾は無いみたい。
VMware上のFedoraでパッケージアップデートしたところ、Emacs-28.3ってのが来ていたり。
正式にリリースされているのだっけ?と思ってWeb検索してみるもソースアーカイブがリリースされている気配は無し。
以前、gitリポジトリ上のChangeLogとかは28.3がリリースされた
かのようなアップデートが行なわれていたのですが、何故かアーカイブがリリースされないという謎な状況です。
セキュリティアップデートとして Fedoraは gitリポジトリから28.3をパッケージ化したという事なのかしら?
逆に言うと Fedora38では Emacs-29.1は来ないという事か...?
2023/10/07
昼過ぎ起床。寝すぎ。
Emacsのmasterブランチのgitログを眺めていて、slurpという画像フォーマット(?)の
組み込み表示対応を行なっているというのを知ったり。
多分 こちら のGitHubリポジトリ
で開発されているのかな?と思ったのですが、日本語でWeb検索しても全然出てこない感じ。
アニメーション系のフォーマットなのか?とも思ったのですがイマイチよく判らず。
そういやWindows11の Segoe UI Emoji で試していなかったと思い確認してみたところ、
どうやら「🧑:ADULT」や「🧒:CHILD」も家族絵文字で結合できるようです。
それらも含めると 234通りで以下のような感じになりました。
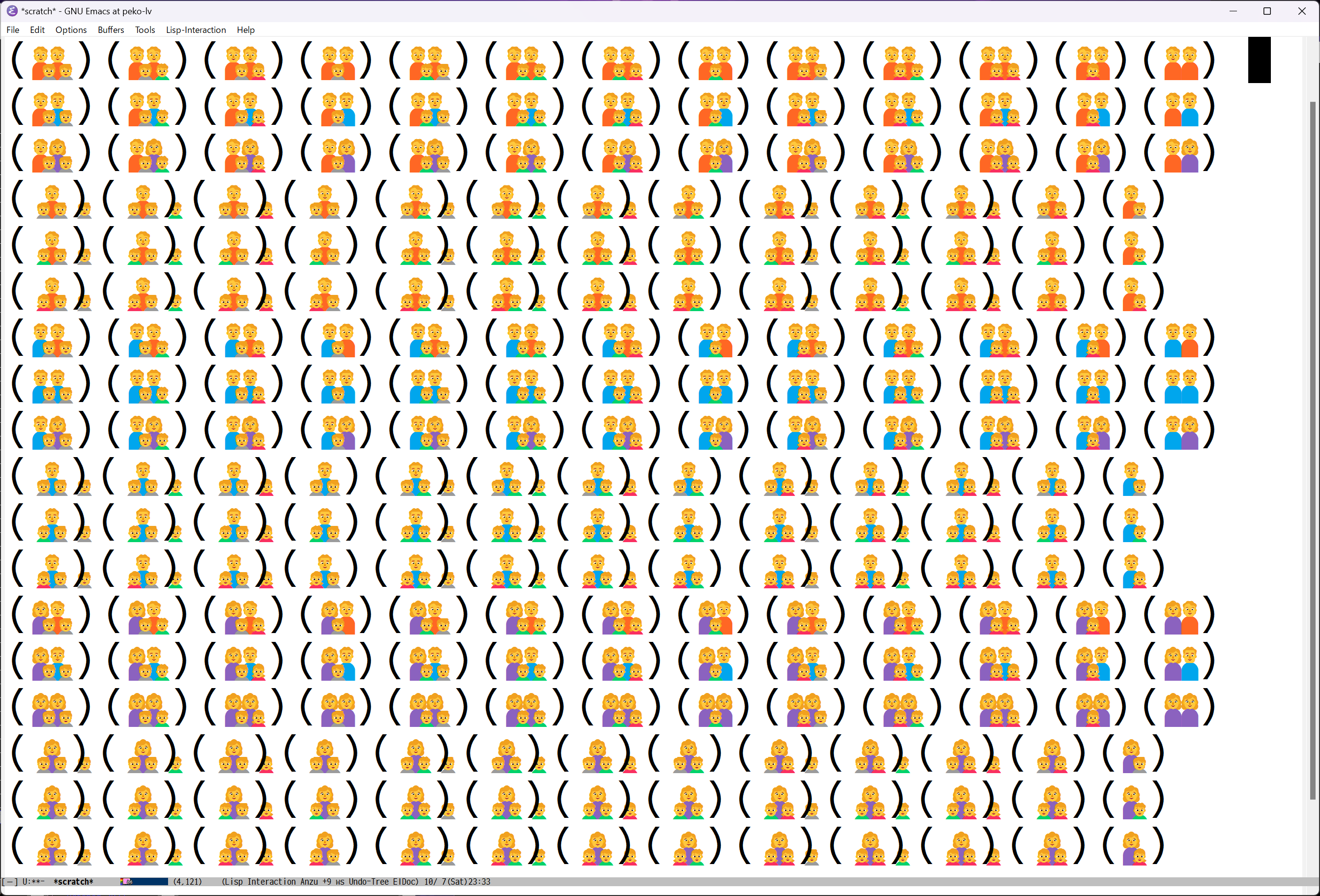
ただ、子供が3人の場合の文字幅が絵と合っていない感じになるみたい。
Edgeでの表示も同じみたいなので、ここはWindows10の Segoe UI Emoji の方が良い感じかも知れません。
あと、以前にも思ったことですが
Windows11の Segoe UI Emoji は絵が細かすぎるように思います。
ところで、職業系の合字がEmacsでは表示されないものがあるみたい。
医者「👨⚕」「👩⚕」「🧑⚕」、裁判官「👨⚖」「👩⚖」「🧑⚖」、パイロット「👨✈」「👩✈」「🧑✈」は、
Windows11では全て合字で表示可能、Windows10だと「🧑:ADULT」以外は表示可能なハズですが、
Emacsでは いずれも合字で表示されませんでした。
定義が無いのだっけ?と思い調べてみたら admin/unidata/emoji-zwj-sequences.txt には
一応定義があって、それに含まれる例示文字は合字で表示できてました。何が違うんだ?と思ったところ、
1F468 200D 2695 FE0F ; RGI_Emoji_ZWJ_Sequence ; man health worker # E4.0 [1] (👨⚕️)
1F468 200D 2696 FE0F ; RGI_Emoji_ZWJ_Sequence ; man judge # E4.0 [1] (👨⚖️)
1F468 200D 2708 FE0F ; RGI_Emoji_ZWJ_Sequence ; man pilot # E4.0 [1] (👨✈️)
1F469 200D 2695 FE0F ; RGI_Emoji_ZWJ_Sequence ; woman health worker # E4.0 [1] (👩⚕️)
1F469 200D 2696 FE0F ; RGI_Emoji_ZWJ_Sequence ; woman judge # E4.0 [1] (👩⚖️)
1F469 200D 2708 FE0F ; RGI_Emoji_ZWJ_Sequence ; woman pilot # E4.0 [1] (👩✈️)
と定義されていて、コードポイント「#xFE0F : VARIATION SELECTOR-16」が必要となっているみたい。
「#xFE0F」が無くても合字で表示できているブラウザの文字をコピペでEmacsに貼り付けると合字で表示されないので
「なんで?」とはなります。どちらが正しいのかは判りませんが、
こういうのは結局「表示できない方が負け」になるので辛い🥺。
ZWJ(#x200D)で結合する流れで考えると、VARIATION SELECTOR-16(#xFE0F)は必要無いようには思えます。
結論、「VARIATION SELECTOR-16 は有っても無くても良い」が正解と思われますが どうなんだろう?🤔
2023/10/06
テレワーク。早くもなく遅くもなく終了。
家族絵文字の組み合わせ。
ソースコードだけですが 作ってみた家族絵文字の生成器を置いておきます
(gen_family_emoji.d)。D言語で書きました。
書いている最中は気にしていませんでしたが、カラー絵文字が表示できないテキストエディタだと
読めないソースコードになっているなぁ?と思ったりも。
uniscribeだと一部豆腐になります。harfbuzzでは肌パターンが結合されてしまうのですが
モノクロ表示だと区別が付きません。
2023/10/05
テレワーク。気持ち早めに終了。
家族絵文字の組み合わせ。
「🧑:person」や「🧒:child」が引っ付かないのは「Segoe UI Emoji」だからか?とも思い、
「Twemoji Mozilla」や「Noto Emoji」でも試してみたのですが引っ付く訳では無さげ。
むしろ「👩👧👦👧」のような4人家族は Segoe UI Emoji の方が良い感じにレンダリングされるような気も。
以下、2~4人構成の表示例。

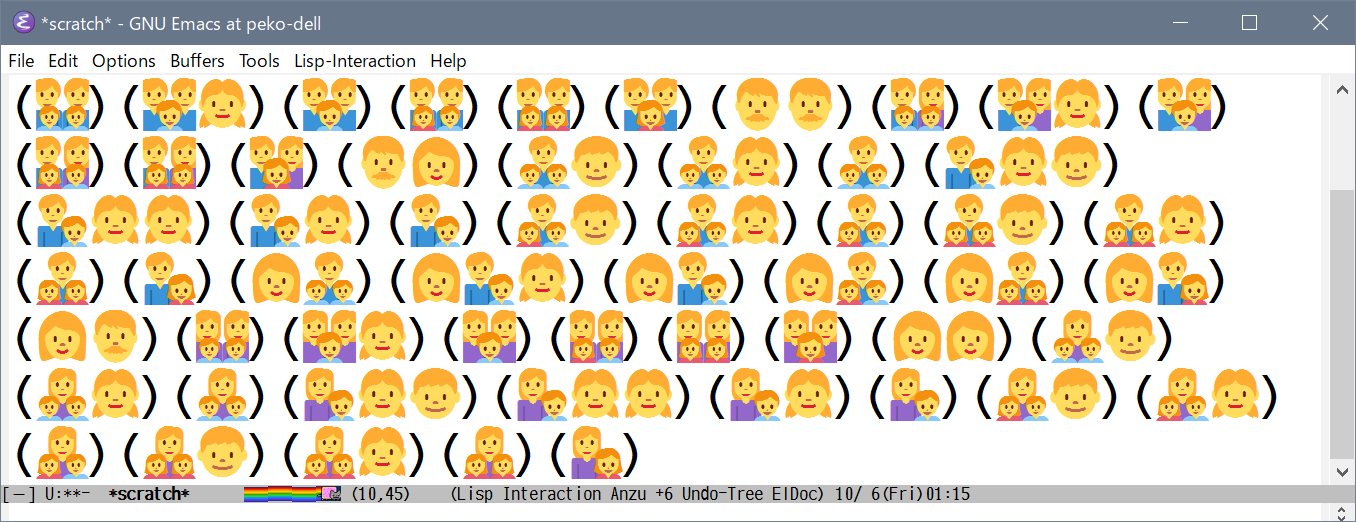
肌パターンとの組み合わせはやはり多すぎるので、今のEmacsの仕組みで対応するのは無理だと思います。
2023/10/04
テレワーク。早くもなく遅くもなく終了。
家族絵文字の組み合わせ。人数分のループで総当たりすると重複ケースが多いなぁ?と思ったり。
なんか競技プログラミングっぽい😅。
重複を踏まないように生成できたような気がしたり。肌パターンは6通りで
親が1~2人でman,womanの組み合わせ、子供が0~3人でboy,girlの組み合わせで、合計人数が2人以上4人以下
となる組み合わせにしたつもりで 不足していなければ45216通りになりました(重複はsort|uniqで確認して無し)。
emacsを makeすると lisp/international/emoji-zwj.el の生成に結構時間がかかりましたが、
一応エラー無くビルド成功。で、emacsを起動してファイルを開いてみるのですが
「Invalid regexp: "Regular expression too big"」ってメッセージがミニバッファに表示されて
動作が怪しい感じになりました。なんかダメそう🥺。
少し減らして、
親が1~2人でman,womanの組み合わせ、子供が0~2人でboy,girlの組み合わせで、合計人数が2人以上3人以下
となる組み合わせにしたつもりで、3744通りになりました。こちらであればビルドもそれほど時間がかからず
ファイルを開くこともできて、組み合わせの絵文字は全て合字で表示されるようになりました。
今の仕組みでは何でもイケるようにするのは難しいかもなぁ?🤔
2023/10/03
テレワーク。早くもなく遅くもなく終了。
家族絵文字の組み合わせを試しに生成してみようと思ったり。
「🧑:person」や「🧒:child」は組み合わせても引っ付かない?とかいくつかの組み合わせは削る必要がありそう。
....なんかうまく書けず🥺
2023/10/02
テレワーク。気持ち早めに終了。
Emacsでの絵文字の合字。
どうやら admin/unidata/emoji-zwj-sequences.txt というファイルに合字として認識できるパターンを記述すれば、
パターンにマッチする組み合わせの合字レンダリングが行なわれるみたい。「👨👩」も定義すれば以下のように
レンダリングできるようです。
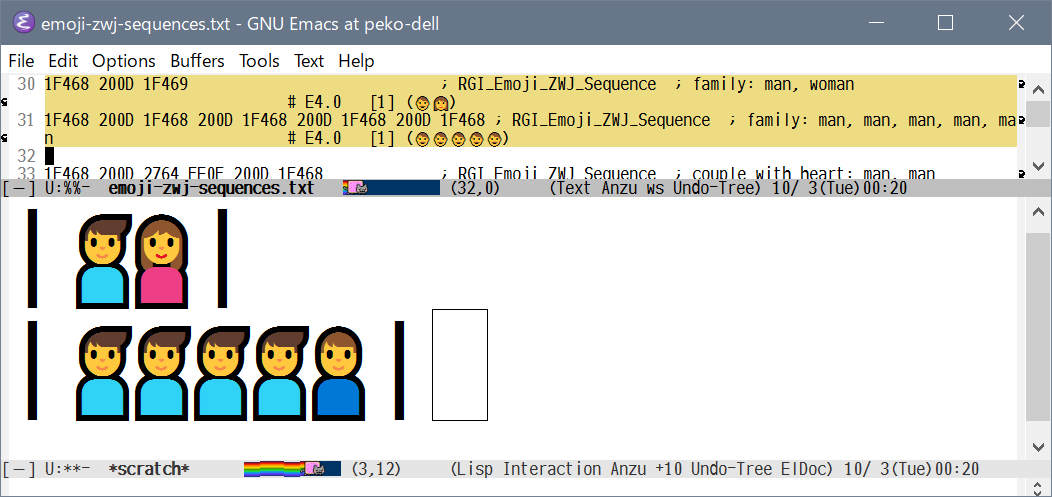
上記Emacs画面画像の上側ウインドウのハイライトした30行目や31行目のように組み合わせを書いて
makeすると、 lisp/international/emoji-zwj.el というELISPが生成されて、それを取り込む事で表示可能となるみたい。
記していない組み合わせは引っ付かないという感じです。
以前試したように並べただけ引っ付くという感じには
今のところはできないかと思われます。また、静的な設定という事になるので、
組み合わせで増やそうとするならば何かしらプログラマブルな表現を行なえる必要があるのだろうなぁ?
と思ったりも。
2023/10/01
AM中に起床。
掃除したり洗濯したり。
Web散策をしていてこちら
のUnicode一覧表示を行なうページを知りました。
「あ(#x3042)」から少し下にスクロールすると量を示す単位の文字が並んでいるなぁと思ったり。
カタカナ表記の日本語文字を押し込んだのは、流石になんでだ?とは思ったりも。
「㌀」や「㍇」の用途なんてほぼ無い気がします😓。
あと、「SI接頭語(Wikipedia)」も
ギガとかテラくらいまでしか無く、ペタやエクサ(いずれも1975年制定)は文字化されていないみたい。
この辺のユニコード文字割り当てって誰が行なったのでしょうね?
Web散策を続けていて、こちらの
Unicodeに関する記事を知りました。このページの一番下の方に Wordを使って絵文字の合字を入力する
動画があるのですが、この記事自体が2016年11月のものなので 7年近く前から Wordでは入力する方法が
あったのか....という事の方に驚いたりも。
Emacsで「C-x 8 RET」を使って16進コードで同じように入力してみたのですが、
肌トーンを指定すると家族として引っ付かず、また、二人だけでも家族として引っ付かないようです。
二人だけでも引っ付かないのはそうなんだっけ?と思ったのですが、「👨👩」をWebブラウザで表示すると
引っ付くようです。家族の絵文字はそういうグリフを表示している訳ではなく(ただし👪は除く)、
部品となるグリフを重ね合わせて表示しています。この為、3人家族(👨👩👦)は表示できるので
2人家族も表示自体は可能と思われます。Emacsではどこで合字として表示可能か否かの決定をしているのだろう?🤔